* boostcourse 카테고리 내의 CS50관련 글은 네이버 부스트코스 [CS50 - 모두를 위한 컴퓨터 과학]을 수강 후 개인적으로 개념을 정리해본 글. 자세한 강의 내용을 확인하고 싶다면 네이버 커넥트재단이 운영하는 boostcourse 사이트에서 상시 무료 수강으로 진행되고 있는 CS50 강의 수강을 추천합니다.
모두를 위한 컴퓨터 과학 (CS50 2019)
부스트코스 무료 강의
www.boostcourse.org
“네이버 커넥트재단은 교육을 통해 개인의 지속적인 성장과 발전을 돕고, 원하는 곳 어디든 배움의 기회가 열리는 세상을 만들기 위해 노력합니다. 부스트코스는 커리어 역량을 강화할 수 있도록, 네이버 커넥트재단에서 기획하고 운영하는 실무형 온라인 교육 프로그램입니다.”
>> 부스트코스 홍보까지는 아니고 ㅎ 무료 강의 추천이다ㅎ
2021/01/10 - [boostcourse] - [부스트코스] CS50 코칭스터디 2기 오리엔테이션
2021/01/16 - [boostcourse] - [부스트코스] CS50 1강: 컴퓨팅 사고 강의 정리
2021/01/22 - [boostcourse] - [부스트코스] CS50 2강: C언어 강의 정리 (부제: 코딩 찌질이)
2021/01/29 - [boostcourse] - [부스트코스] CS50 3강: 배열 강의 정리 (부제: 코칭스터디 3주차)
2021/02/05 - [boostcourse] - [부스트코스] CS50 4강: 알고리즘 강의 정리 (부제: 아직 2주나 혹은 벌써 2주 남은 코칭 스터디)
2021/02/12 - [boostcourse] - [부스트코스] CS50: 초보자는 헷갈리는 C언어 용어 정리
2021/02/14 - [boostcourse] - [부스트코스] CS50 5강: 메모리 강의 정리 (부제: 설연휴 만세)
CS50 6강 자료구조(Data Structures)
- malloc과 포인터 복습
- 배열의 크기 조정하기
- 연결 리스트: 도입
- 연결 리스트: 코딩
- 연결 리스트: 시연
- 연결 리스트: 트리
- 해시 테이블
- 트라이
- 스택, 큐, 딕셔너리
2021/03/03 - [boostcourse] - [부스트코스] CS50 코칭스터디 2기 수료 후기
1. malloc과 포인터 복습
int main(void)
{
int *x;
int *y;
x = malloc(sizeof(int));
*x = 42;
*y = 13;
}예시코드는 오류가 포함된 코드로, 한 줄씩 차례차례 살펴보면 아래와 같다.
int main(void)
{
int *x; //정수형 포인터 x 생성
int *y; //정수형 포인터 y 생성
// 정수 크기만큼 malloc함수를 이용하여 메모리를 할당함
x = malloc(sizeof(int));
*x = 42; //x에 저장된 주소로 가서 42를 저장함
*y = 13; //y에 저장된 주소로 가서 13을 저장하는데, 변수에 메모리를 할당하지 않았으므로 오류에 해당
}*는 역참조 연산자로, 해당하는 주소로 가라는 의미를 가진다. *y의 경우, 초기화되지 않았기 때문에 프로그램의 어딘가를 임의로 가리키고 있을 수 있다. 만약 데이터가 저장되어 있는 임의의 공간에 정수 값을 저장하게 되면 오류가 발생하게 되므로, 코드의 수정이 필요하다.
int main(void)
{
int *x;
int *y;
x = malloc(sizeof(int));
*x = 42;
y = x;
*y = 13;
}y가 x와 같다는 코드 y = x;를 한 줄 추가할 경우, *y는 *x와 같은 주소값을 같게 되므로 최종적으로 42대신 13이 저장된다. 추가적으로 메모리를 할당하지 않고 덮어쓰는 방식으로 문제를 해결했다.
2. 배열의 크기 조정하기(realloc)
#include <stdio.h>
int main(void)
{
int list[3];
list[0] = 1;
list[1] = 2;
list[2] = 3;
for(int i = 0; i < 3; i++)
{
printf("%i\n",list[i]);
}
}위의 예시 코드처럼 크기가 3인 배열을 저장했으나 이후 배열의 크기를 늘려야 하는 경우가 생길 수 있다. 이때, 단순히 배열에 인덱스를 하나 추가하면 될 것 같지만, 컴퓨터의 메모리에는 다양한 데이터들이 저장되어 있기 때문에 배열에 할당된 공간 주변에도 다른 데이터들이 둘러싸고 있을 확률이 높다. 따라서 새로운 빈 공간에 기존의 배열 크기 + 추가하고 싶은 크기만큼의 메모리를 할당한 이후 배열을 옮겨주는 작업이 필요하다.
| D | A | T | A | \0 |
| M | A | P | \0 | 1 |
| 2 | 3 | M | A | P |
| \0 | ||||
표를 통한 메모리 내부 시각화: 크기가 3인 배열
| D | A | T | A | \0 |
| M | A | P | \0 | |
| M | A | P | ||
| \0 | ||||
| 1 | 2 | 3 | 4 |
배열을 옮긴 후 요소 추가하기
이렇게 배열을 옮기는 작업은 배열의 크기만큼의 시간이 걸리기 때문에, O(n)만큼의 시간이 소요된다(엄밀히는 왕복의 과정이므로 2n이지만, 유의미한 값이 아니므로 생략).
소스코드로 나타내면 아래와 같다(메모리 할당에 대한 시범을 보이기 위한 코드이기 때문에 코드가 비효율적임을 감안할 것).
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
//int 자료형 3개로 이루어진 list 라는 포인터를 선언하고 메모리 할당
//맨 위의 예시코드와 달리 malloc을 이용하여 보다 동적으로 메모리를 할당했다.
int *list = malloc(3 * sizeof(int));
// 컴퓨터 혹은 클라우드의 메모리가 부족한 상황 등의 오류가 생길 경우, 1을 반환
if (list == NULL)
{
return 1;
}
// list 배열의 각 인덱스를 직접입력하는 하드 코딩. 즉, 수동으로 값을 저장.
list[0] = 1;
list[1] = 2;
list[2] = 3;
//int 자료형 4개 크기의 tmp라는 포인터를 선언하고 메모리 할당(새로운 공간을 할당받음)
int *tmp = malloc(4 * sizeof(int));
if (tmp == NULL)
{
return 1;
}
// list의 값을 tmp로 복사
for (int i = 0; i < 3; i++)
{
tmp[i] = list[i];
}
// tmp배열의 네 번째 값도 저장
tmp[3] = 4;
// list의 메모리를 초기화
free(list);
// list가 tmp와 같은 곳을 가리키도록 지정
list = tmp;
// 새로운 배열 list의 값 확인(인덱스가 하나 추가되었으므로 숫자는 4가됨)
for (int i = 0; i < 4; i++)
{
printf("%i\n", list[i]);
}
// list의 메모리 초기화
free(list);
}그러나 이 코드에서처럼 직접 메모리를 할당하고 해제할 필요없이 realloc을 사용하여 보다 간단하게 구성할 수도 있다.
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int *list = malloc(3 * sizeof(int));
if (list == NULL)
{
return 1;
}
list[0] = 1;
list[1] = 2;
list[2] = 3;
// tmp 포인터에 메모리를 할당하고 list의 값 복사.
// 기존의 for 반복문이 생략되어 보다 간결해졌다.
int *tmp = realloc(list, 4 * sizeof(int));
if (tmp == NULL)
{
return 1;
}
// list가 tmp와 같은 곳을 가리키도록 지정
list = tmp;
// 새로운 list의 네 번째 값 저장
list[3] = 4;
// list의 값 확인
for (int i = 0; i < 4; i++)
{
printf("%i\n", list[i]);
}
//list 의 메모리 초기화
free(list);
}realloc 또한 <stdlib.h>에 속한 함수로, 이미 할당받은 기존의 메모리를 가져온 다음 원래보다 크든 작든 새롭게 설정된 크기로 바꾸는 작업을 수행한다.
3. 연결 리스트(linked list): 도입 (typedef struct)
배열은 대괄호를 이용하여 쉽게 인덱싱한 뒤 원하는 위치로 바로 접근할 수 있기 때문에 빠르며 특히 정렬된 형태일 경우에는 이진 검색 등에 적용할 수 있다는 장점이 있다. 그러나 2. 배열의 크기 조정에서 살펴본 것처럼 배열은 고정된 메모리 덩어리이기 때문에 배열의 크기를 조정해서 더 많은 값을 넣어주고 싶을 경우엔 새로운 메모리 할당 > 배열 복사 > 기존 배열 메모리 해제라는 복잡한 과정을 거치게 된다. 이 과정은 O(n)이 되므로 배열의 크기가 클 수록 오래 걸린다.
매번 위와 같은 과정을 반복하는 대신, 자료 구조를 통해 보다 효율적으로 메모리를 사용할 수도 있다. 자료 구조(데이터 구조)는 컴퓨터 메모리를 더 효율적으로 관리하기 위해 새로 정의하는 구조체를 말하는데, 그 중에서 아래의 세가지를 통해 '연결 리스트'를 구현해 볼 수 있다.
struct(구조체).(점 연산자) : 구조체의 속성값을 가져올 때 사용*(역참조 연산자) : 메모리로 접근할 때 사용
(참고로 1번과 2번의 경우에는 4강 알고리즘> 3. 선형 검색> 3.1 배열관련 TIP> 3.1.3 구조체를 이용하여 배열에 여러가지 정보를 함께 저장하기에서 짧게 다뤘던 내용이다.)
연결리스트를 이용할 경우, 배열의 크기 조정 때처럼 계속해서 추가할 수 있을 만큼 메모리가 남아있기를 바라는 대신, 모든 요소들을 서로서로 옆에 붙일 수 있다.

크기가 1인 배열(또는 리스트라 명명)이 있고, 다소 떨어진 위치에 작은 여유 메모리들이 있다는 가정 하에 추가로 2와 3을 저장한 그림이다. 이 경우 각 요소들이 떨어져 있기 때문에 대괄호를 사용할 수 없다.
분산되어 있는 값들을 연결하기 위해, 각각의 값에 두 배의 메모리를 주어 포인터 주소를 저장해보면 아래와 같은 그림이 된다.

1의 다음에 2가 올 수 있도록 추가로 부여한 메모리에 주소 값을 저장하고, 2 역시 마찬가지로 추가 메모리에 3의 주소 값을 저장한다. 3 이후의 값이 없을 때에는 리스트의 끝을 알리는 NULL을 저장한다. 이때 NULL은 문자열의 \0과 똑같이 0이라는 값을 가지지만 의미가 다른데, NULL은 포인터의 역할이다. 16진법 0x0의 값을 가진다.
이 구조를 개별적을 살펴보면 숫자(number)와 주소 값(관례적 표현으로 next사용)이라는 두 가지로 이루어져 있다. 소스코드로 구조체를 정의해 보면 아래와 같다.
typedef struct node
{
int number;
struct node *next;
}
node;
컴퓨터 공학에서 노드(node)는 직사각형으로 나타낼 수 있는 메모리 덩어리를 의미하며 여러 목적에 의해 사용할 수 있다고 한다. 즉, 그림에서 보이는 직사각형들을 노드라고 보고 구조체에도 그 이름을 썼다.

이전 강의에서 구조체를 정의했을 때처럼 간단하게 코드를 작성하지 않고 코드 상단 typedef struct뒤에 node를 적어준 이유는, 아래와 같이 구조를 정의할 경우엔 node가 마지막 줄 이전에는 사실상 존재하지 않는 값이기 때문이다. 소스코드 작성시 함수를 사용하기 위해서 프로토 타입을 먼저 입력 후 함수를 사용하는 것과 비슷한 맥락으로, 구조체 안에서 node를 사용하기 위해선 상단에 사용하고자 하는 단어를 추가해야 한다.
//오류코드 예시
typedef struct
{
int number;
node *next;
}
node;//수정 후
typedef struct node //'구조체의 정식 명칭': 참고로 상단의 이름은 node가 아니라 어떤 이름이라도 될 수 있다.
{
int number;
struct node *next; //그러나 상단의 이름과 이 행에 쓰인 이름은 같아야 한다.
//강의에서는 관례상 세 가지(상단, 구조체 내부, 하단) 모두 같은 용어를 사용했다.
}
node; //'구조체의 별명'
4. 연결 리스트: 코딩
4.1 연결 리스트 생성
3. 연결 리스트: 도입(typedef struct)에서 살펴본 개념을 적용해 실제로 연결 리스트를 만들어보기 위해, 먼저 비어있는 리스트를 만들어준다.
typedef struct node
{
int number;
struct node *next;
}
node;
int main(void)
{
node *list = NULL;
}
그림으로 나타내보면 아래 그림처럼 비어있는 상자의 형태를 띨 것이다.

아래 그림은 이 상태에서 list에 넣을 node가 메모리 어딘가에 하나 추가되어있다고 가정한 것이다.

그림처럼 node값을 변수 n에 저장한 뒤 숫자를 저장하는 코드는 아래와 같이 작성해 볼 수 있다(메인 함수 생략).
node *n = malloc(sizeof(node));
(*n).number = 2;이 때 (*n).number = 2;는 node의 number을 2로 설정한다는 뜻인데, 연산의 순서(컴파일러가 먼저 인식 후 처리할 수 있도록)를 위해 괄호를 넣어주다보니 코드가 다소 복잡해졌다. 화살표와 같은 모양을 띠는 ->를 이용해서 보다 간단하게 바꿔줄 수 있다.
node *n = malloc(sizeof(node));
n->number = 2;(*n).number = 2;와 같은 뜻이지만, 더 명확하게 의미를 전달하면서도 간결하다.
node *n = malloc(sizeof(node));
n->number = 2;
n->next = NULL;NULL값도 추가하여 node를 나타내는 코드를 완성했다. 하지만 malloc은 반환된 값을 항상 체크해주는 것이 좋다.
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = 1;
n->next = NULL;보다 정밀한 코드를 위해 if 조건문을 추가했다.
이때 변수 n은 node 그 자체가 아니고 주소 값을 가지는 변수임을 유념해야 한다. 주소 값이기 때문에 아래와 같은 코드를 구성하게 된다.
- 화살표 기호 사용
n.number,n.next와 같은 구조를 사용할 수 없음*를 붙인 뒤에야.을 사용할 수 있음
여기까지는 list와 node n의 코드를 살펴본 것으로 아직 연결하는 과정은 실행되지 않은 상태다.
따라서 list의 NULL값이 node n의 number를 가리키도록 하는 작업이 필요하다. list는 아무 값도 가지고 있지 않기 때문에, 연결은 간단하게 list = n;을 통해 이루어질 수 있다. 이 코드로 인해 list의 NULL은 n의 number를 가리키는 포인터 값을 가지게 된다.

연결 후에 또 다른 node를 list에 추가하고 싶을 경우, 새로운 node를 우선 할당받는다.
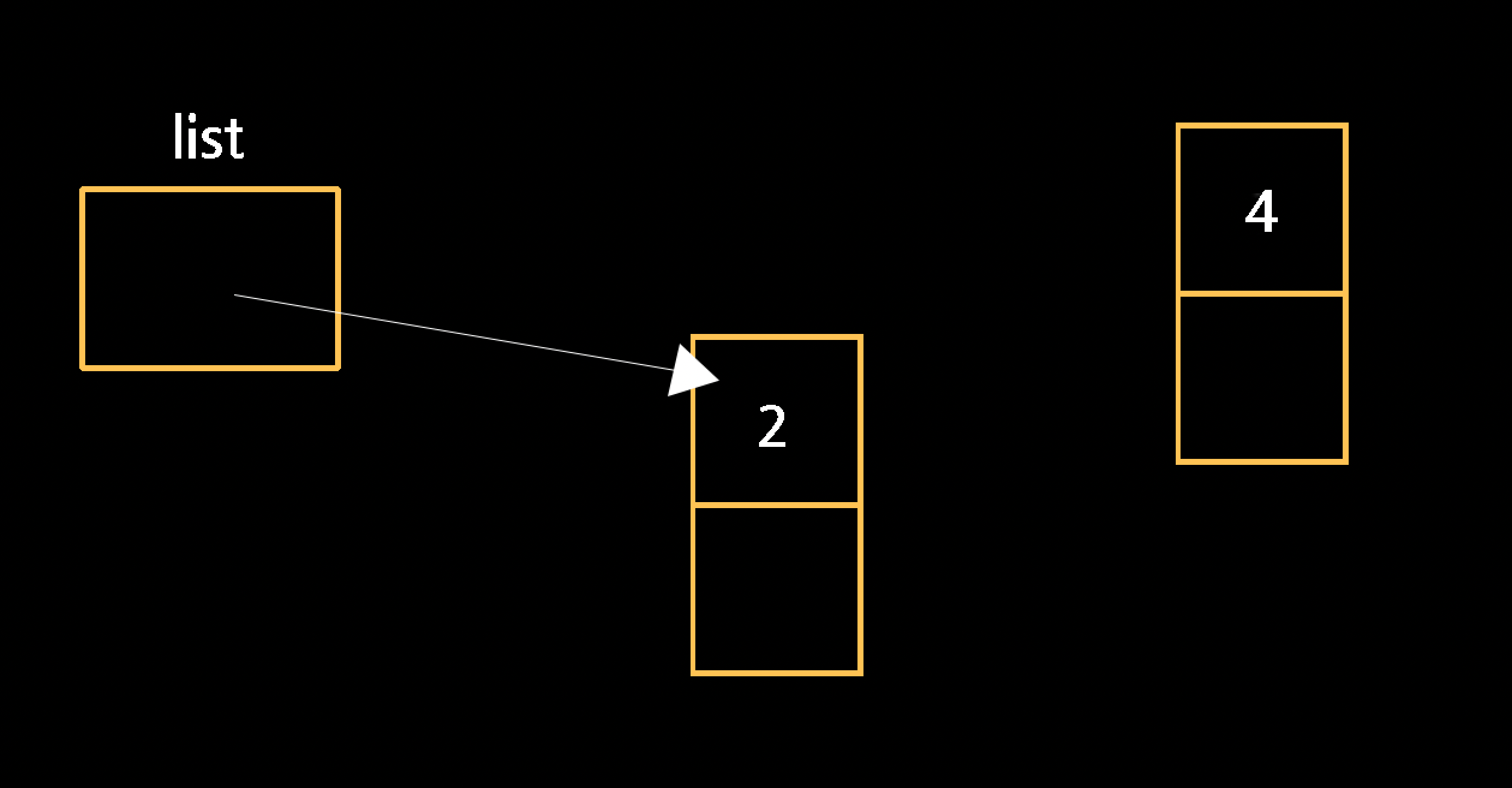
이때 list가 4를 가르키도록 하면 기존에 연결되어있던 2는 버려지기 때문에, 2의 next 포인터가 4를 가르키도록 해야한다. 이 과정을 위해 임시로 tmp 포인터를 선언 후 list를 가리킨 다음에 해당 리스트의 끝인 NULL을 찾아 가도록 한 뒤에야 4와 연결시킬 수 있다. 코드로 나타내면 아래와 같다.
node *tmp = list; //tmp가 list와 같은 곳을 가리키도록 선언
while (tmp->next !=NULL) //NULL이 아니라면
{
tmp = tmp-> next //계속해서 자신을 업데이트 후 그 자신이 가리키고 있는 것을 가리키도록 함
}
tmp->next = n; //NULL이라면 node n을 가리키도록 함
4.2 기존의 연결 리스트 중간에 요소 추가하기
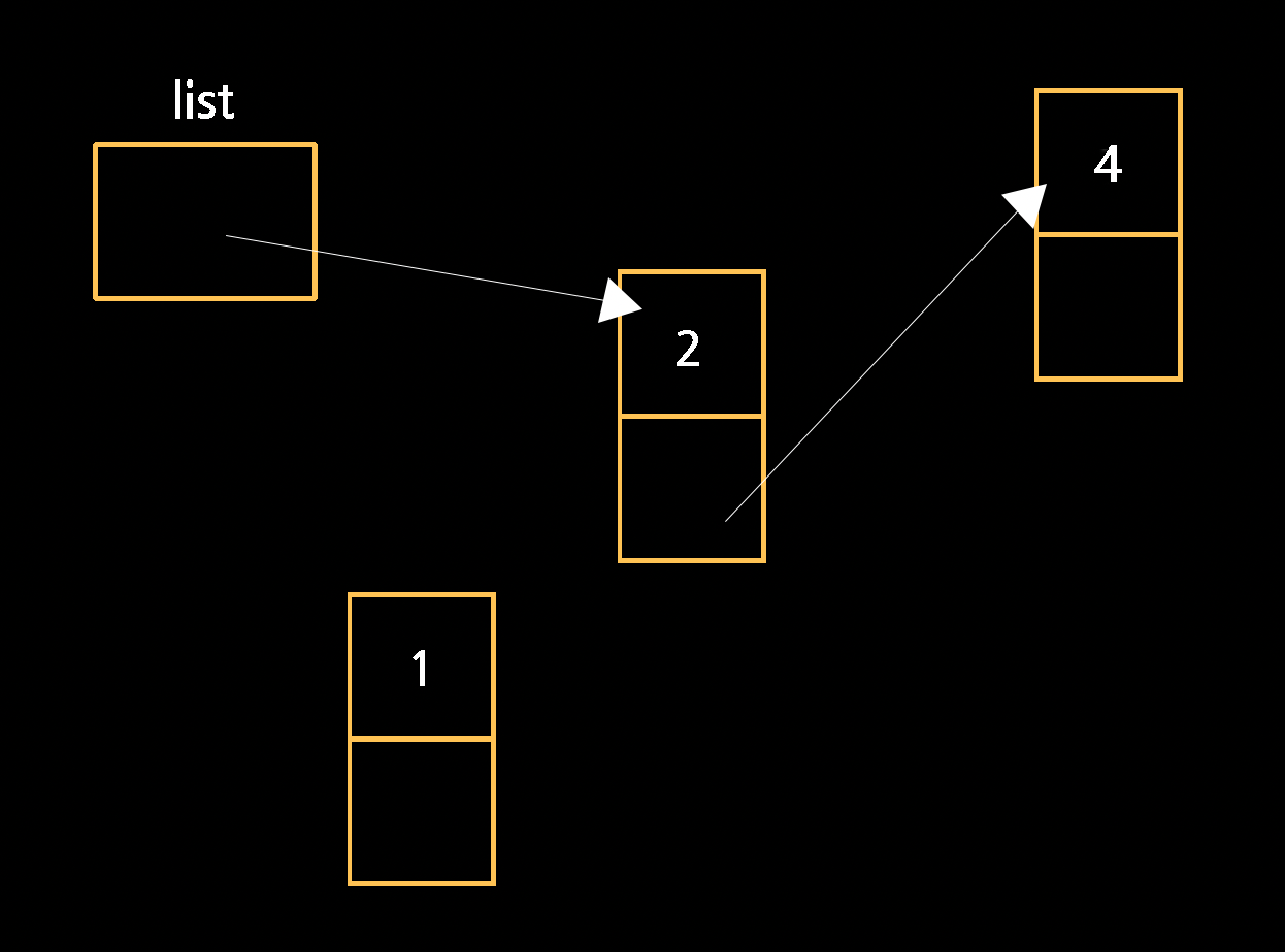
기존에 있는 연결리스트의 끝이 아닌, 중간에 요소를 추가해야할 경우가 생길 수 있다. 예시 그림의 경우, 새로운 요소인 1을 맨 앞에 추가해야하는 상황이다.

이때 list를 바로 1과 연결 후 1과 나머지 연결된 것들을 연결할 수 있을 것 같지만, 앞서 언급했듯 list가 1과 연결되는 순간 2, 4는 버려지게 되므로 옳지 않다. 만약 free하는 것을 잊는다면 메모리 누수의 문제로까지 이어질 수도 있다. 더 심한 경우에는 이 메모리들에 다시는 접근할 수 없을지도 모르는데, 이 값들이 어디에 있는지 기억하고 있는 변수가 없기 때문이다.
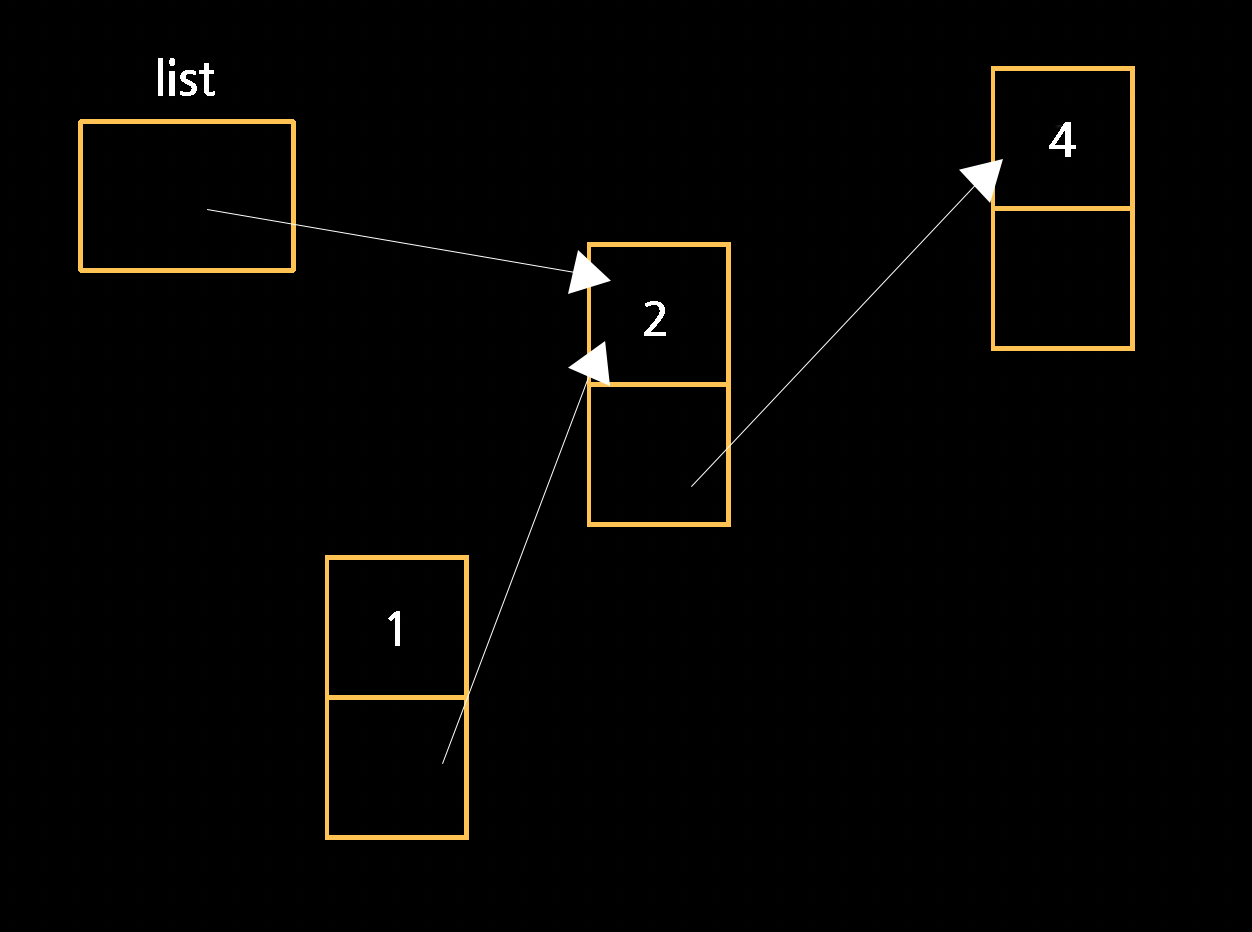
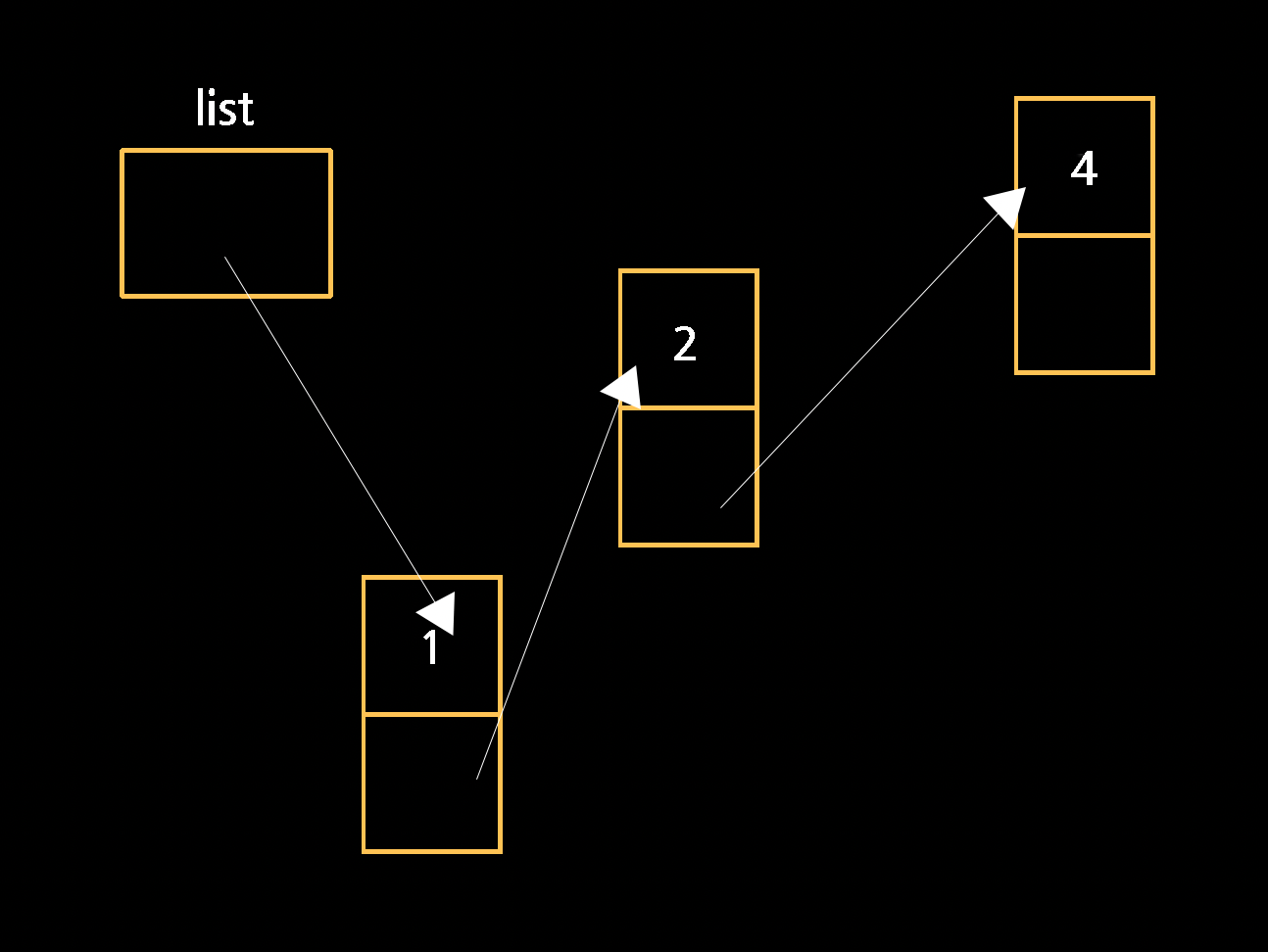
그러므로 우선 1이 list와 같은 곳을 가리키도록한 뒤에 list가 1을 가리키도록 해주어야 한다.
n->next = list;
list = n;코드로 나타내면 위와 같다. 새로운 node n의 next가 list와 같음을 선언한 뒤, list가 n 그 자체를 가리키도록 하는 것이다.
만약, 또 다시 중간에 요소를 추가해야하는 경우가 생길 경우에도 위와 같은 과정을 통해 추가해줄 수 있다. 간단하게 그림을 통해 살펴보면 아래와 같다.


2가 바로 3을 가리키지 않고, 3이 먼저 2와 같이 4를 가리키도록 한다.
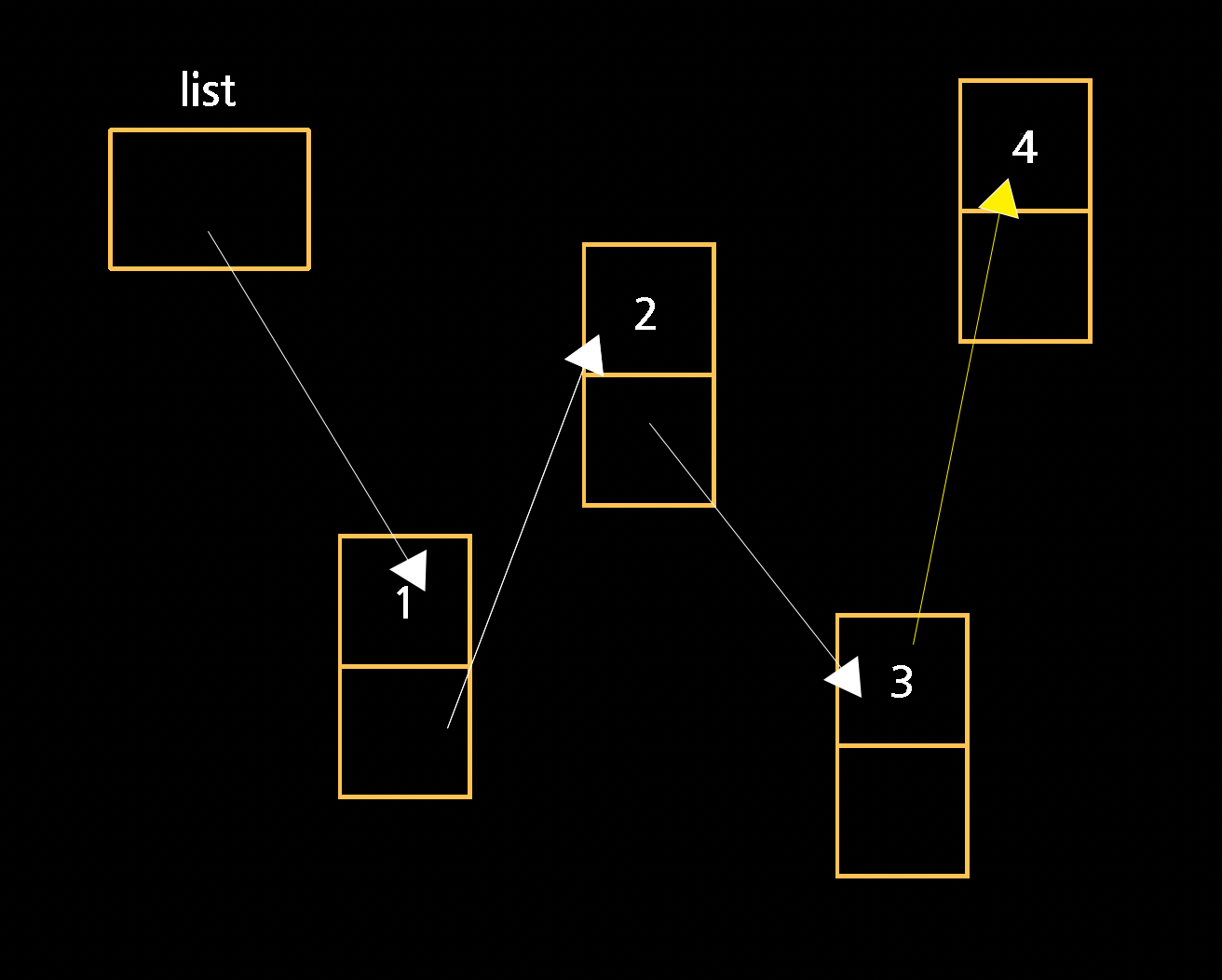
그 다음 2의 next가 node n을 가리키도록 해준다.
그림으로 살펴보면 간단한 과정이지만, 코드로 작성할 경우엔 보다 복잡한 단계를 거치게 된다.
- 먼저 루프를 이용해서 원래 존재하던 리스트를 탐색한다 : 반복문
- 부등호를 사용해 새로운 요소를 삽입할 적절한 위치를 찾아낸다 : 대소비교
- 삽입 과정을 진행하기 위해 새로운 포인터를 생성한다 : 포인터 업데이트
순서를 지키는 것이 중요하지 않은 상황에서 연결 리스트에 요소를 추가해야 할 경우, 맨 앞에 추가하는 것이 가장 쉽고 그 다음으로는 마지막에 추가하는 것이 쉽다.
5. 연결 리스트: 시연
5.1 직접 시연해보기
강의에서는 연결 리스트를 연결하는 과정에 대한 개념 설명 이후 강의 수강생들이 직접 시연해보는 과정을 가졌다. 앞선 그림을 통한 설명이 잘 이해되지 않았다면, 시연 과정을 통해 보다 쉽게 이해할 수 있을 것 같다. 그런데 수강생들이 시연을 지원할 때 이렇게 여러 나라의 사람들이 본인들의 시연을 지켜보게 될 거라는걸 알았을까? ㅋㅋㅋ
5.2 연결리스트의 장점과 단점 (배열과의 비교)

다시 그림 설명으로 돌아가서, 여태껏 그림을 통해 연결리스트를 살펴볼 때 우리는 어느 위치에 어느 값이 있는지 바로 알아볼 수 있었지만, 실제로 컴퓨터는 아래처럼 연결 리스트라는 형태만 알 수 있다(강의에서는 1부터 5까지 추가해서 설명해서 node가 하나 더 추가되어 있다).

따라서 컴퓨터는 각 위치에 어떤 값이 있는지 살펴보기 위해 일일이 모든 메모리를 확인해야만 한다.

그러므로 각각의 값을 모두 보기 위해선(검색 또는 탐색으로 표현) O(n)이 된다. 또한 이러한 방법으로 리스트 내의 값을 볼 때는 포인터를 따라 흘러가듯이 살펴보기 때문에 원하는 요소에 바로 접근할 수가 없다. 즉, 임의 접근이 불가능하다. 이렇게 임의 접근이 불가능할 경우, 임의 접근 방법이 전제되는 이진 검색 역시 사용할 수 없게 된다.
마찬가지로 삽입의 과정 또한 모든 리스트를 둘러 본 후에 주어진 값에 맞는 자리를 찾아야 하므로 역시 O(n)이 된다.
2. 배열의 크기 조정하기에서 보았듯 배열의 경우에는 크기를 늘리기 위해 새로운 메모리 할당 > 배열 복사 > 기존 배열 메모리 해제의 복잡한 과정을 거쳤다. 반면에 연결 리스트는 원하는 만큼 동적으로 리스트를 추가할 수 있다는 장점이 있다. 대신 임의 접근과 이진 검색이 불가능한 단점을 가지게 되는 것이다.
| 연결 리스트 | |
| 장점 | 단점 |
| 요소끼리 동적으로 연결 가능 | 요소 삽입 시 모든 리스트를 살펴보는 과정이 필요: O(n) |
| 동적 연결을 통한 효율적인 메모리 사용 가능 | 임의 접근 불가 |
| (배열 내 요소 추가 과정과 달리) 비교적 간단한 과정 | 임의 접근 불가로 인한 이진 검색 불가 |
| 배열 | |
| 장점 | 단점 |
| 배열 내 요소에 임의 접근 가능 | 배열 내에 새로운 요소를 추가할 경우 새로운 메모리 할당> 배열 복사> 기존 배열 메모리 해제의 복잡한 과정 필요 |
| 임의 접근이 가능하기 때문에 이진 검색 가능 | 동적이지 못함 |
4강 알고리즘> 8. 병합 정렬(merge sort)> 8.1 병합 정렬(합병 정렬)에서 정리한 실행시간 정리 표에 추가 후 비교·정리해보면 아래와 같다.
| 실행 시간의 상한 |
실행 시간의 하한 |
||
| O(n^2) | 버블 정렬, 선택 정렬 | Ω(n^2) | 선택 정렬 |
| O(n log n) | 병합 정렬 | Ω(n log n) | 병합 정렬 |
| O(n) | 선형 검색, + 연결리스트 탐색(search)🆕, + 연결리스트 삽입(insert)🆕 |
Ω(n) | 버블 정렬 |
| O(log n) | 이진 검색 | Ω(log n) | |
| O(1) | Ω(1) | 선형 검색, 이진 검색 | |
그러나 이 표는 완성형이 아니다. 6. 연결 리스트: 트리를 통해 수정될 예정. 우선적으로 '선형' 연결 리스트에 해당한다고 생각하면 된다.
5.3 연결 리스트를 만드는 과정 코드 정리
3. 연결 리스트: 도입 (typedef struct)부터 4. 연결 리스트: 코딩까지의 과정을 한 번에 코드로 정리해보면 아래와 같다. 리스트 중간에 요소를 추가하는 과정없이 순차적으로 리스트를 구성하되 3까지만 추가 후 메모리를 해제하는 과정까지 정리되어 있다.
#include <stdio.h> //printf를 사용하기 위해 포함.
#include <stdlib.h> //malloc과 free를 사용하기 위해 포함.
//연결 리스트의 기본 단위가 되는 node 구조체를 정의.
typedef struct node
{
//node 안에서 정수형 값이 저장되는 변수를 name으로 지정.
int number;
//다음 node의 주소를 가리키는 포인터를 *next로 지정.
struct node *next;
}
node;
int main(void)
{
// list라는 이름의 node 포인터를 정의. 연결 리스트의 가장 첫 번째 node를 가리키게 됨.
// 이 포인터는 현재 아무 것도 가리키고 있지 않기 때문에 NULL 로 초기화.
node *list = NULL;
// 새로운 node를 위해 메모리를 할당하고 포인터 *n으로 가리킴.
// malloc 사용 시에는 반환값 체크 필요(if 조건문).
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
// n의 number 필드에 1의 값을 저장. “n->number”는 “(*n).numer”와 동일한 의미.
// 즉, n이 가리키는 node의 number 필드를 의미.
// 간단하게 화살표 표시 ‘->’ 사용 후 n의 number의 값을 1로 저장.
n->number = 1;
// n 다음에 정의된 node가 없으므로 next는 NULL로 초기화.
n->next = NULL;
// 첫번째 node를 정의했으므로 list 포인터를 n 포인터로 바꿈.
list = n;
// list에 다른 node를 더 연결하기 위해 n에 새로운 메모리를 다시 할당.
n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
// n의 number와 next의 값을 각각 저장.
n->number = 2;
n->next = NULL;
// list가 가리키는 것은 첫 번째 node이므로
// 이 node의 다음 node를 n 포인터로 지정.
list->next = n;
// 다시 한 번 n 포인터에 새로운 메모리를 할당하고 number과 next의 값을 저장.
n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = 3;
n->next = NULL;
// 현재 list는 첫번째 node를 가리키고, 첫번째 node는 두번째 node와 연결되어 있는 상태.
// 따라서 세 번째 node를 더 연결하기 위해 첫 번째 node (list)의
// 다음 node(list->next)의 다음 node(list->next->next)를 n 포인터로 지정.
list->next->next = n;
// 이제 list에 연결된 node를 처음부터 방문하면서 각 number 값을 출력.
// 마지막 node의 next에는 NULL이 저장되어 있으므로 이것이 for 루프의 종료 조건이 됨.
for (node *tmp = list; tmp != NULL; tmp = tmp->next)
{
printf("%i\n", tmp->number);
}
// 메모리를 해제해주기 위해 list에 연결된 node들을 처음부터 방문하면서 free 해줌.
while (list != NULL)
{
node *tmp = list->next;
free(list);
list = tmp;
}
}
6. 연결 리스트: 트리(tree)
위의 과정에서 다룬 연결 리스트들은 결과적으로 아래와 같은 형태의 1차원적인 리스트로, 메모리 사용의 차이 외에 최종적 형태는 배열과 크게 다르지 않았다.

그러나 연결 리스트의 경우엔 포인터를 활용하여 가계도와 같은 형태의 2차원적 구성을 만들 수도 있다.

다시 배열로 돌아가서, 어떻게 2차원적인 구성으로 발전시킬 수 있는지 과정을 정리했다.

먼저 리스트의 중간으로 간 뒤, 왼쪽이나 오른쪽의 중간 값으로 간다.

여기서 다시 왼쪽과 오른쪽을 살펴보면 아래와 같은 모습이 된다.

위와 같은 과정에 높이 차를 준다면 2차원적 구성이 될 수 있다.
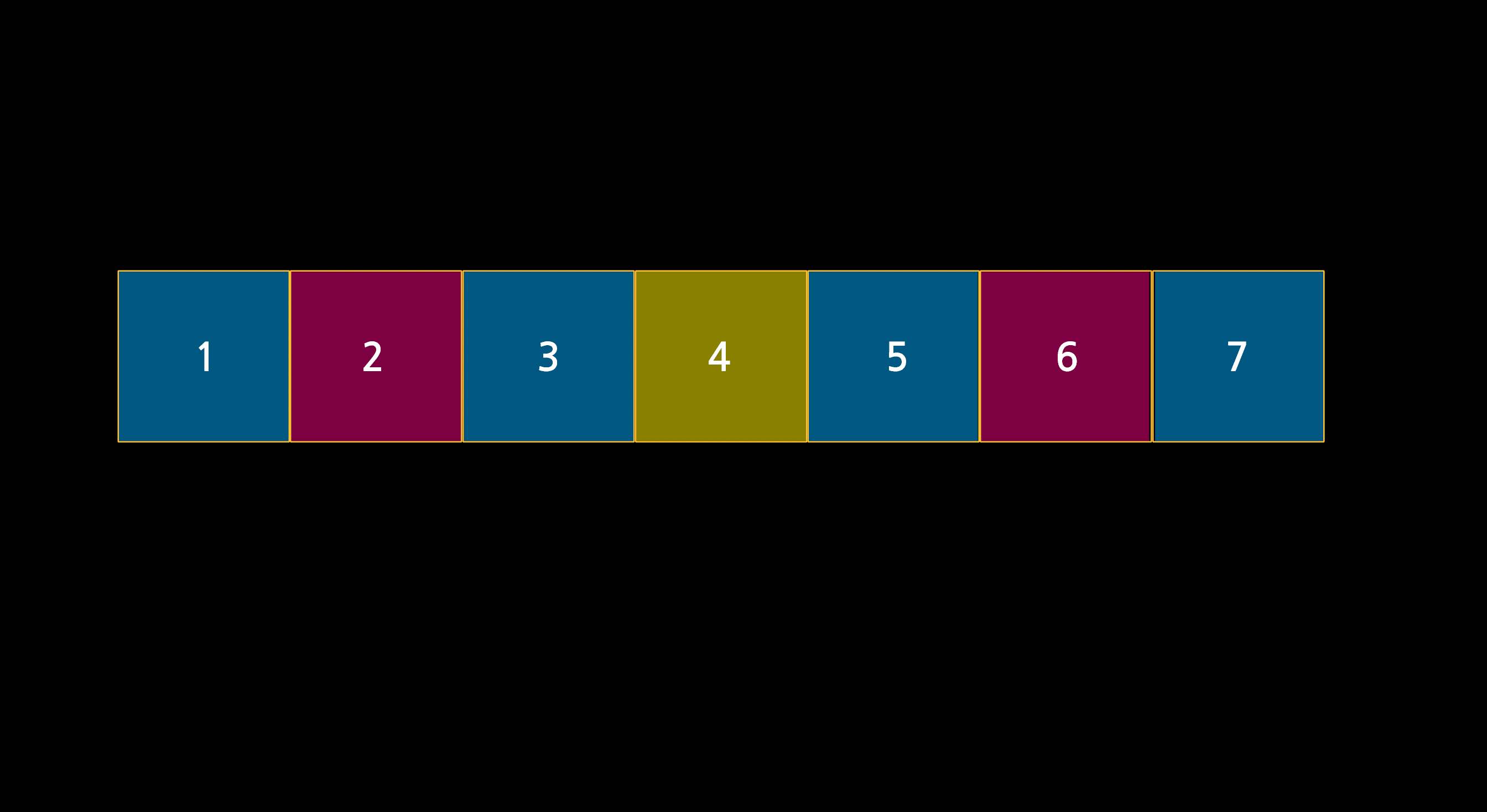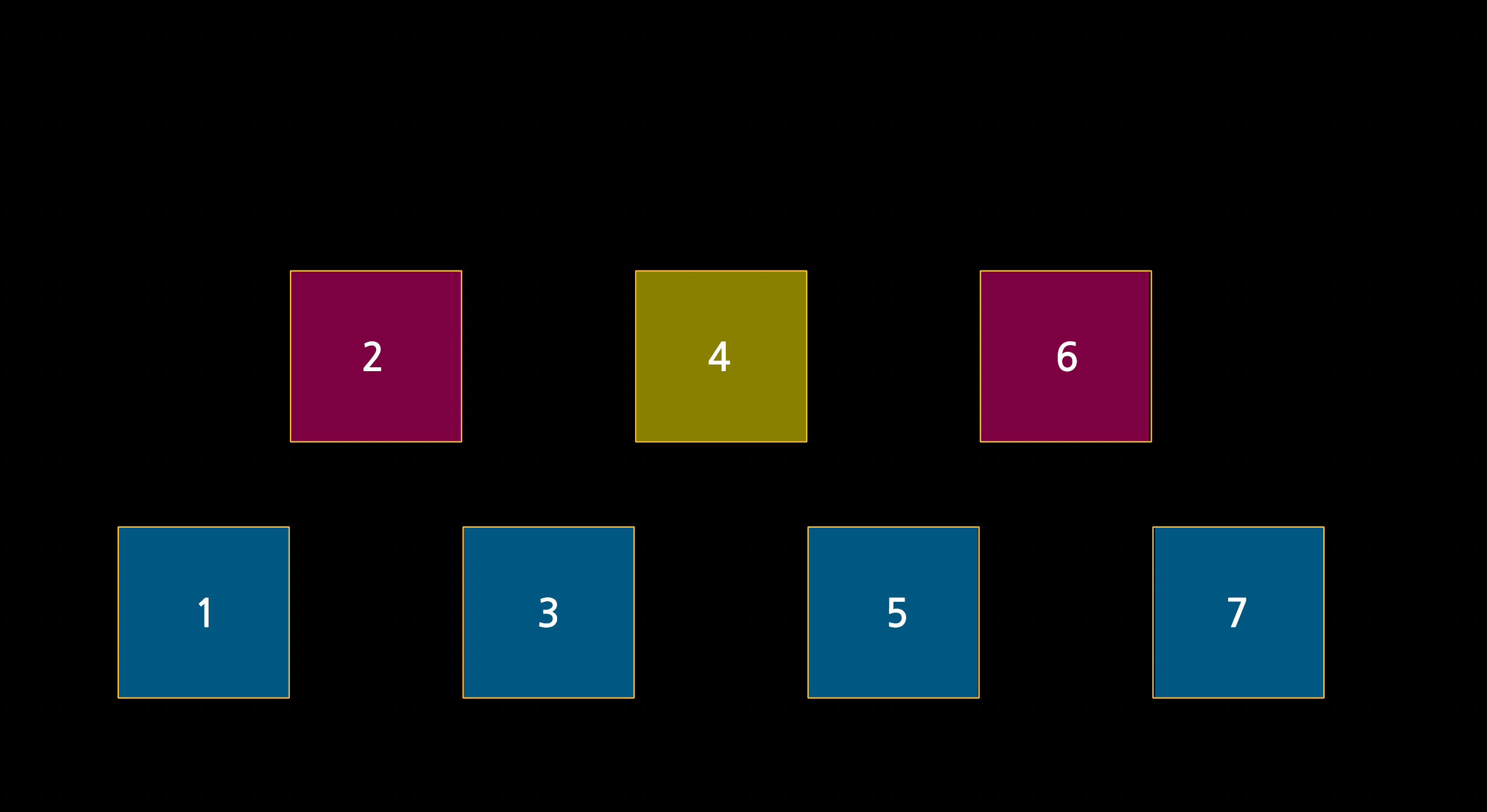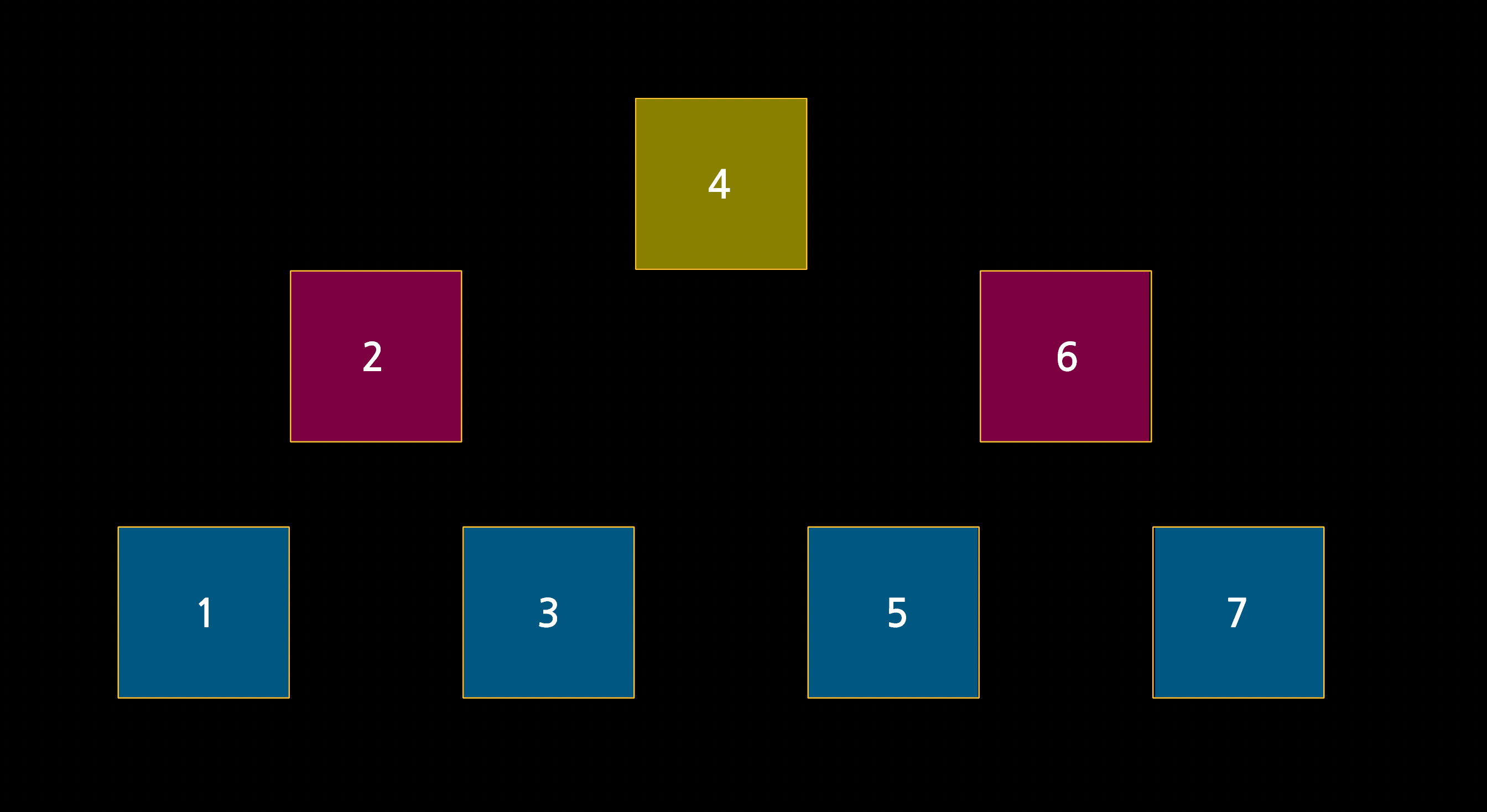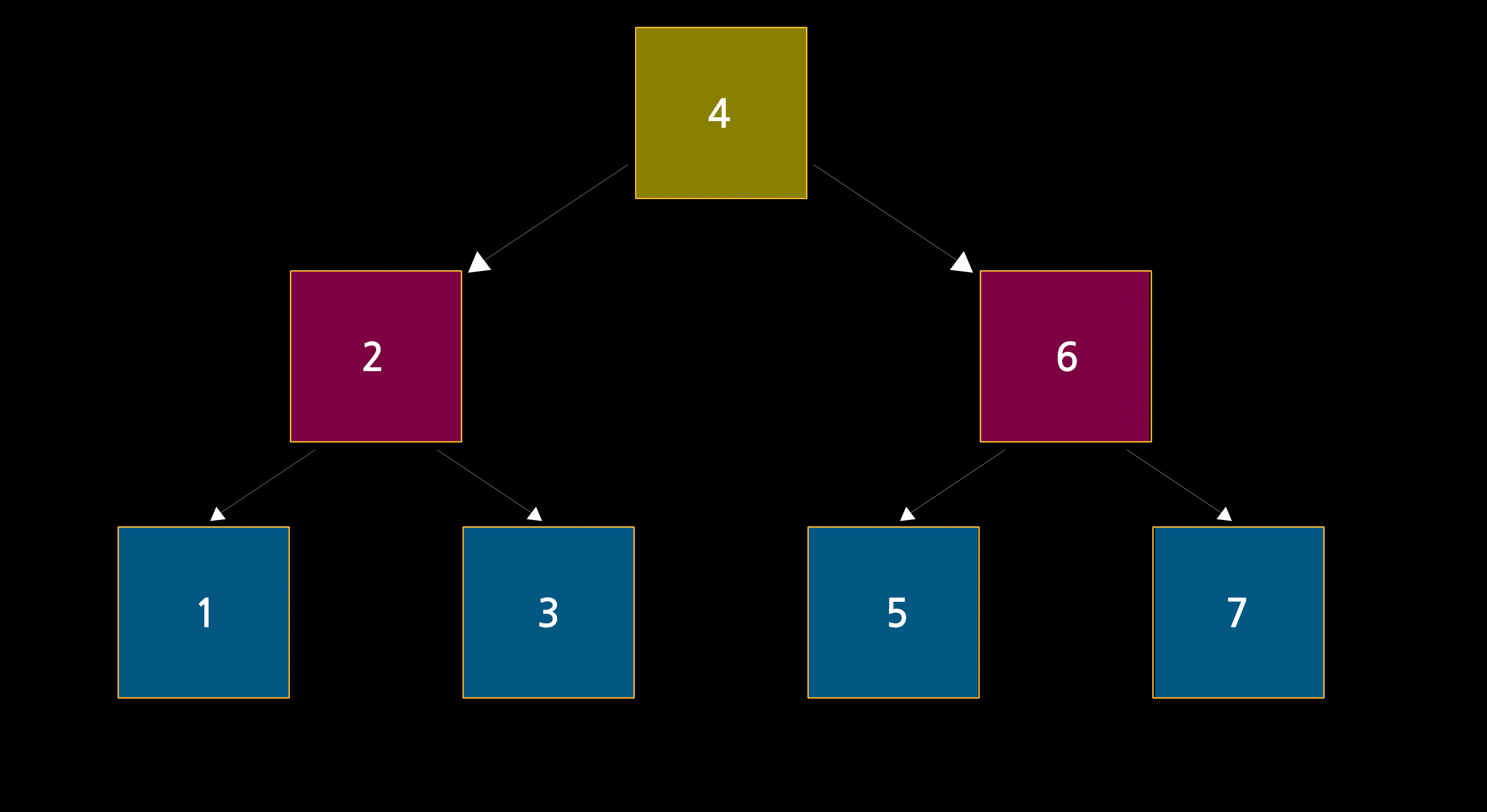
(화살표 선이 잘 안보이는데, 눈을 부릅😳뜨고 보면 가는 선이 보인다. 클릭해야 끝까지 재생됨.)
그림의 화살표는 결국 포인터이므로, 위 과정의 핵심은 node가 가리키는 포인터가 하나가 아니라 두 개가 되도록 추가해주는 것이다. 이렇게 완성된 형태를 '이진 탐색 트리'라고 한다.
- 최대 2개의 하위 노드를 가짐: 이진
- 순서를 맞추기 위해 신경을 씀: 검색, 탐색
위와 같은 특성에 따라 '이진 탐색 트리'라고 하는 것이다. 참고로 하위의 node는 '자식 노드'라고 부른다. 예시의 경우, 4의 자식 노드는 2와 6이 되며 2의 자식노드는 1과 3, 6의 자식 노드는 5와 7이 된다. 맨 마지막 줄은 자식 노드가 없다.
typedef struct node
{
int number;
struct node *left;
struct node *right;
}
node;코드로 구현하면 위와 같다. 왼쪽과 오른쪽 두가지 포인터를 추가한 것을 볼 수 있다.
그리고 트리에 있는 모든 노드들은 왼쪽 자식 노드가 더 작다. 따라서 이름에서 드러나듯 이진 탐색 트리는 이진 검색(binary search)이 가능하다. 기존 선형 연결 리스트와 마찬가지로 포인터를 이용하여 역동성을 가지면서도 이진 검색까지 가능한 장점을 갖는다. 메모리의 어디에 위치하든지 포인터를 이용하여 트리를 추가할 수 있으며 그 끝에는 루트(예시의 경우 4)가 위치한다. 컴퓨터 공학에서의 트리(tree)의 루트(root)는 위 아래가 뒤집힌 형태다.
정수로 이루어진 임의의 이진 검색 트리에서 '50'을 찾는 코드를 작성해본다면 아래와 같다.
//이진 검색 트리의 노드 구조체
typedef struct node
{
// 노드의 값
int number;
// 왼쪽 자식 노드
struct node *left;
// 오른쪽 자식 노드
struct node *right;
} node;
// 이진 검색 함수 (*tree는 이진 검색 트리를 가리키는 포인터)
// 정확히는 트리의 핵심인 루트를 가리킴
// 찾는 숫자가 있으면 true, 아니면 false를 반환
bool search(node *tree)
{
// 트리가 비어있는 경우 ‘false’를 반환하고 함수 종료
if (tree == NULL)
{
return false;
}
// 현재 노드의 값이 50보다 크면 왼쪽 트리(노드) 검색
// 부모에서 자식으로 내려가더라도 부분 또한 다시 트리가 되므로 재귀가 적용된다
else if (50 < tree->number)
{
return search(tree->left);
}
// 현재 노드의 값이 50보다 작으면 오른쪽 트리(노드) 검색
else if (50 > tree->number)
{
return search(tree->right);
}
// 위 모든 조건이 만족하지 않으면 노드의 값이 50이므로 ‘true’ 반환
else {
return true;
}
}
이진 탐색 트리는 구조 자체가 이진 검색이 적용된데다 코드 내 주석에서 언급한 것처럼, 재귀적이므로 실행 시간의 상한은 O(log n)이 된다.
트리에 요소를 추가(insert)할 경우를 계산하기에 앞서, 만약 트리에 계속해서 작은 숫자를 넣거나 계속해서 큰 숫자만 넣을 경우에는 트리의 크기가 얇고 길어지게 될 것이다. 이 경우 트리가 균형을 잃게 되기 때문에 균형을 유지할 수 있도록하는 알고리즘이 따로 있다고 한다. 그러나 이렇게 하더라도 여전히 삽입 실행 시간은 O(log n)이다.
| 실행 시간의 상한 |
실행 시간의 하한 |
||
| O(n^2) | 버블 정렬, 선택 정렬 | Ω(n^2) | 선택 정렬 |
| O(n log n) | 병합 정렬 | Ω(n log n) | 병합 정렬 |
| O(n) | 선형 검색, '선형' 연결리스트 탐색, '선형' 연결리스트 삽입 |
Ω(n) | 버블 정렬 |
| O(log n) | 이진 검색, + 이진 탐색 트리 탐색(search)🆕 + 이진 탐색 트리 삽입(insert)🆕 |
Ω(log n) | |
| O(1) | Ω(1) | 선형 검색, 이진 검색 | |
7. 해시 테이블(hash table)
해시테이블은 배열과 연결리스트를 조합한 개념으로 정확히는 '연결 리스트의 배열'이다. 자료 구조를 잘 구현한다면 매우 빠른 속도를 가질 수 있다.



예시는 이해를 돕기 위해 배열을 세로로 놓은 것이다. 해시테이블의 배열에서 각 값(여기서는 이름)들은 '해시 함수'라는 맞춤형 함수를 통해 어떤 배열에 위치할지 결정되는데, 예시의 경우에는 '이름의 첫 글자'를 알파벳 순서에 따라 저장하는 방식이다. 만약 이미 어떤 값이 해당 배열 내에 속해있을 경우에는 연결 리스트로 이어지게 된다.

컴퓨터가 값(이름)들을 저장할 때에는 임의 접근 방법을 통해 바로바로 저장할 수 있는데, 만약 모든 항목에 1개씩 밖에 값이 들어있지 않다면 실행 시간의 상한은 O(1)이 된다.
그러나 예시의 경우 G, H, L, R, S의 경우 항목이 1개가 초과됐기 때문에 O(1)이 될 수 없다. 컴퓨터 공학에서는 이렇게 어떤 값을 넣으려고 하는데 이미 무언가가 들어있는 경우를 충돌이라고 한다. 만약 이 해시테이블에 넣어야 하는 이름이 예시보다 훨씬 많아진다면, 배열에 위치하게 되는 값들의 충돌이 증가하여 실행 시간의 상한은 O(n)이 된다.
예시의 충돌을 없애기 위해 해시 함수를 '이름의 첫글자'가 아니라 '이름의 처음+두번째 글자'로 증가시킨다고 할 경우, 배열의 크기는 26x26이 되어 총 676칸의 배열이 필요하다. 그러나 이렇게 하더라도 여전히 Harry와 Hagrid는 충돌한다. '이름의 처음+두번째 글자+세번째 글자'로 늘릴 경우 문제는 해결되지만 예시에만 국한될뿐, 넣어야 하는 이름이 더 많아질 경우에는 장담할 수 없다. 따라서 얼마나 많은 공간을 사용할 것인지(해시테이블의 크기) 아니면 이상적인 해시 함수를 찾기 위해서 노력을 기울일 것인지와 같은 공간과 시간의 싸움이 된다. 그래도 모든 이름을 연결 리스트나 배열에 넣는 것보다는 해시 테이블로 구분지어서 찾는 것이 훨씬 낫다.
| 실행 시간의 상한 |
실행 시간의 하한 |
||
| O(n^2) | 버블 정렬, 선택 정렬 | Ω(n^2) | 선택 정렬 |
| O(n log n) | 병합 정렬 | Ω(n log n) | 병합 정렬 |
| O(n) | 선형 검색, '선형' 연결리스트 탐색(search), '선형' 연결리스트 삽입(insert), 해시 테이블🆕 |
Ω(n) | 버블 정렬 |
| O(log n) | 이진 검색, 이진 탐색 트리 탐색(search) 이진 탐색 트리 삽입(insert) |
Ω(log n) | |
| O(1) | Ω(1) | 선형 검색, 이진 검색, 해시 테이블🆕 |
|
8. 트라이(tries)
7. 해시테이블과 같이 이름을 정리해야 하는 상황에서 또 다른 자료 구조로 '트라이(tries)'를 시도해 볼 수도 있다. 트라이는 검색(retrieval)의 줄임말로, 이름처럼 검색에 특화되어 있는 자료구조이다.

위 그림은 트라이 구조로 Hagrid, Harry, Hermione 이름 세 개를 저장한 것이다. 각각의 노드(예시의 경우 a-z)가 배열로 이루어지기 때문에 맨 위의 배열이 트라이의 루트가 된다.
트라이에 이름을 하나 저장할 때에는 이름의 모든 글자를 봐야하는데 예시의 Harry의 경우, H, a. r, r, y 총 다섯 글자로 나뉘어진다. 글자로 나뉜 이름의 끝에서는 불리언 연산식을 이용하여 이름이 끝났다는 것을 표시한다.
이름을 찾기 위한 과정도 이름의 글자 수와 같은 단계를 거친다. H, a, r, r, y를 모두 살펴봐야 Harry임을 알 수 있기 때문이다. 그러나 이름의 경우에는 아무리 길다고 하더라도 길이에 한계가 있고(아무리 길어도 30글자를 초과하진 않을 것이다), 한계가 있다는 것은 곧 고정 값을 갖게 됨을 의미한다. 컴퓨터 공학에서 이처럼 고정된 상한은 상수라고 부른다. 상수는 O(k)이므로 최종적으로 실행시간은 O(1)이 된다.
| 실행 시간의 상한 |
실행 시간의 하한 |
||
| O(n^2) | 버블 정렬, 선택 정렬 | Ω(n^2) | 선택 정렬 |
| O(n log n) | 병합 정렬 | Ω(n log n) | 병합 정렬 |
| O(n) | 선형 검색, '선형' 연결리스트 탐색(search), '선형' 연결리스트 삽입(insert), 해시 테이블 |
Ω(n) | 버블 정렬 |
| O(log n) | 이진 검색, 이진 탐색 트리 탐색(search) 이진 탐색 트리 삽입(insert) |
Ω(log n) | |
| O(1) | 트라이 탐색🆕 트라이 삽입🆕 |
Ω(1) | 선형 검색, 이진 검색, 해시 테이블 |
그러나 트라이는, 그림에서 드러나듯 3개의 이름을 저장하는데도 많은 노드를 사용하기 때문에 빠른 속도 대신 많은 메모리를 차지한다는 단점이 있다.
9. 스택(stack), 큐(queue), 딕셔너리(dictionary)
9.1 큐(queue)
- 값이 아래로 쌓이는 구조
- FIFO(first-in, fisrt-out | 선입선출)의 자료 구조
- enqueue(인큐): 줄에 들어가서 서는 것
- dequeue(디큐): 줄을 빠져나오는 것
- 예시: 가게나 식당 앞의 대기줄, 은행 대기표 순서, 프린트 출력 순서 등
9.2 스택(stack)
- 값이 위로 쌓이는 구조
- LIFO(last-in, first-out | 후입선출)의 자료 구조
- push(삽입): 스택에 요소를 밀어 넣음
- pop(삭제): 가장 위의 요소를 뺌
- 예시: 뷔페에 쌓인 접시, 학생 식당에 쌓인 식판, 메일함의 메일들
9.3 딕셔너리(dictionary)
- 해시테이블과 비슷한 개념
- key(키)에 해당하는 value(값)를 저장함
- 예시: 학번과 학생
마지막 강의를 끝낸 심정

정말 이게 끝이라고?
배워야할 건 아직도 구만리겠구나 하는 생각
코칭 스터디 2기 관련 내용은 다른 포스트로 작성 예정

'STUDY > boostcourse' 카테고리의 다른 글
| [부스트코스] CS50 코칭스터디 2기 수료 후기 (0) | 2021.03.03 |
|---|---|
| [부스트코스] CS50 5강: 메모리 강의 정리 (부제: 설연휴 만세) (0) | 2021.02.14 |
| [부스트코스] CS50: 초보자는 헷갈리는 C언어 용어 정리 (0) | 2021.02.12 |
| [부스트코스] CS50 4강: 알고리즘 강의 정리 (부제: 아직 2주나 혹은 벌써 2주 남은 코칭 스터디) (0) | 2021.02.05 |
| [부스트코스] CS50 3강: 배열 강의 정리 (부제: 코칭스터디 3주차) (0) | 2021.01.29 |