* boostcourse 카테고리 내의 CS50관련 글은 네이버 부스트코스 [CS50 - 모두를 위한 컴퓨터 과학]을 수강 후 개인적으로 개념을 정리해본 글. 자세한 강의 내용을 확인하고 싶다면 네이버 커넥트재단이 운영하는 boostcourse 사이트에서 상시 무료 수강으로 진행되고 있는 CS50 강의 수강을 추천합니다.
모두를 위한 컴퓨터 과학 (CS50 2019)
부스트코스 무료 강의
www.boostcourse.org
“네이버 커넥트재단은 교육을 통해 개인의 지속적인 성장과 발전을 돕고, 원하는 곳 어디든 배움의 기회가 열리는 세상을 만들기 위해 노력합니다. 부스트코스는 커리어 역량을 강화할 수 있도록, 네이버 커넥트재단에서 기획하고 운영하는 실무형 온라인 교육 프로그램입니다.”
>> 부스트코스 홍보까지는 아니고 ㅎ 무료 강의 추천임 ㅎ
2021/01/10 - [boostcourse] - [부스트코스] CS50 코칭스터디 2기 오리엔테이션
2021/01/16 - [boostcourse] - [부스트코스] CS50 1강: 컴퓨팅 사고 강의 정리
2021/01/22 - [boostcourse] - [부스트코스] CS50 2강: C언어 강의 정리 (부제: 코딩 찌질이)
2021/01/29 - [boostcourse] - [부스트코스] CS50 3강: 배열 강의 정리 (부제: 코칭스터디 3주차)
2021/02/05 - [boostcourse] - [부스트코스] CS50 4강: 알고리즘 강의 정리 (부제: 아직 2주나 혹은 벌써 2주 남은 코칭 스터디)
2021/02/12 - [boostcourse] - [부스트코스] CS50: 초보자는 헷갈리는 C언어 용어 정리
CS50 5강 메모리(Memory)
- 메모리 주소
- 포인터
- 문자열
- 문자열 비교
- 문자열 복사
- 메모리 할당과 해제
- 메모리 교환, 스택, 힙
- 파일 쓰기
- 파일 읽기
2021/02/23 - [boostcourse] - [부스트코스] CS50 6강: 자료구조 강의 정리 (부제: CS50 수강 완료!)
2021/03/03 - [boostcourse] - [부스트코스] CS50 코칭스터디 2기 수료 후기
1. 메모리 주소
1.1 16진법(Hexadecimal notation)
컴퓨터 과학에서는 숫자를 10진수나 2진수 대신 16진수(Hexadecimal)로 표기하는 경우가 많다. 많은 양의 데이터를 처리하기에 편리하기 때문. 2진법과 10진법, 16진법을 표로 한 눈에 비교해보면 차이를 알 수 있다.
| 이진수 (4비트) | 십진수 | 십육진수 |
| 0 0 0 0 | 0 | 0 |
| 0 0 0 1 | 1 | 1 |
| 0 0 1 0 | 2 | 2 |
| 0 0 1 1 | 3 | 3 |
| 0 1 0 0 | 4 | 4 |
| 0 1 0 1 | 5 | 5 |
| 0 1 1 0 | 6 | 6 |
| 0 1 1 1 | 7 | 7 |
| 1 0 0 0 | 8 | 8 |
| 1 0 0 1 | 9 | 9 |
| 1 0 1 0 | 10 | A |
| 1 0 1 1 | 11 | B |
| 1 1 0 0 | 12 | C |
| 1 1 0 1 | 13 | D |
| 1 1 1 0 | 14 | E |
| 1 1 1 1 | 15 | F |
8bit(1byte)로 표현할 수 있는 가장 큰 숫자인 255(0부터 세기 때문에 0을 하나의 수로 보고 256이 아닌 255가 된다)를 다시 각 진법에 맞게 표기하면 아래와 같다.
| 2진수 | 1 1 1 1 1 1 1 1 | 1 1 0 1 1 0 0 0 |
| 10진수 | 255 | 216 |
| 16진수 | 0xff | 0xd8 |
이때 16진수는 8비트를 4비트찍 쪼개어 표현한 값이다. 216의 경우, 1 1 0 1 | 1 0 0 0 이렇게 4비트씩 나누어 16진수로 계산한 것이다. 2개의 16진수는 1바이트의 2진수로 변환되기 때문에 정보를 표현하기에 유용하다. 16진 수 앞의 0x는 수학적으로는 아무 의미도 없지만, 16진수임을 나타내기 위해 쓰인다.

참고로 의식하진 못했더라도 한 번쯤 다들 접해볼 수 있는 16진수 중의 하나는 색상 값이다. 위의 캡처처럼, 티스토리 블로그 글쓰기에서도 볼 수 있다. 예시의 FFFFFF가 흰색이므로 반대로 모든 값이 000000인 색은 검정색이다.
1.2 컴퓨터 메모리


간단하게 정수를 출력하는 코드를 작성했을 때, 컴퓨터 내의 메모리 어딘가에 변수 n의 값이 저장되어 있을 것이다. 3강 배열> 4. 배열> 4.1 컴퓨터 메모리(RAM)에서 다뤘던 내용처럼, int는 4바이트이므로 메모리 어딘가에 4바이트만큼의 값을 차지하게 된다.

이 때, 정확히 메모리의 어떤 위치에 저장된 것인지 알고 싶을 경우엔 코드에서 n의 주소를 출력해주면 된다.

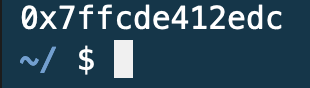
&는 '~의 주소'를 의미하는 연산자다. 변수앞에 &를 붙여준 뒤, %p 형식지정자로 변경하여 주소를 출력할 수 있도록 해주면 메모리의 주소를 볼 수 있다. p는 포인터의 약자로, 포인터는 곧 메모리 주소 값을 가리킨다. 이렇게 출력된 주소는 16진수로 표현된다.
여기서 반대의 기능을 하는 연산자 *를 통해 다시 원래의 값을 불러올 수 있다.


바로 전의 코드에서는 &n을 통해 n이 위치한 주소 값을 출력했다. 여기에 보통 곱셈으로 자주 쓰이는 *을 추가해볼 수 있는데, 이 때는 일반적인 의미(곱셈)와 달리 '해당하는 주소로 감'을 뜻한다(*는 문맥에 따라 다른 의미를 갖는다). 따라서 *&n을 입력하여 값이 위치한 주소를 얻고 다시 그 주소에 해당하는 값을 가져오도록 한 뒤, %i로 출력하면 원래 값이 나오는 것을 볼 수 있다. 참고로 일반적으로 &과 *을 같이 쓰지는 않지만, 연산의 이해를 위해 강의에서 다룬 것이다.
2. 포인터
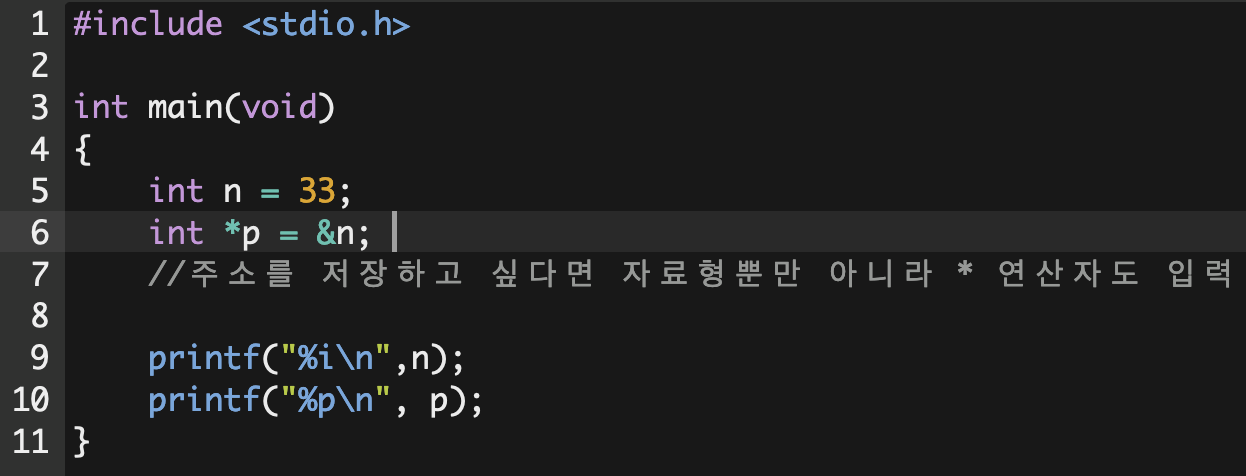

위의 코드처럼 *를 이용하여 포인터 역할을 하는 변수를 선언해볼 수도 있다. p앞의 *은, 해당 변수가 포인터의 역할을 하고 있음을 뜻하고, int는 포인터가 int 타입의 변수를 가리키고 있다는 의미이다(int n의 주소를 저장하고 있기때문). 코드를 컴파일 후 실행해보면 문제없이 16진수를 출력해낸다. 참고로 이 주소는 출력을 반복해보면 알겠지만, 계속해서 다른 값을 출력하는데 최근 컴퓨터들은 보안상의 문제로 메모리 위치를 여기저기로 바꾸기 때문이라고 한다.

예시코드를 가상의 메모리 그림으로 시각화 해보면 위와 같은 형태를 띨 것이다. 그림처럼 포인터는 n의 두배가 되는 값을 가지는데, 실제로도 꼭 그런 것은 아니지만 대부분 이렇게 동작한다고 한다. 또한 최신 컴퓨터의 경우에는 64bit 포인터를 사용하기 때문에 8바이트 또는 64비트라고 할 수 있고, 마찬가지로 정수형(int)은 4바이트 또는 32비트가 된다.

다시 포인터로 돌아와서, 포인터의 주소 값은 중요하지 않으므로 포인터가 n을 가리키고 있다는 점만 기억하면 된다. 이러한 포인터를 기반으로 다양한 데이터 구조를 정의하고 사용할 수 있다.
3. 문자열 + CS50의 string

지금까지 CS50라이브러리 내에서 문자열을 사용할 때에는 string이라는 형식지정자를 사용했다. 3강 배열> 5. 문자열과 배열> 5.1 문자열의 의미에서 살펴봤듯이 문자열(string)은 결국 문자(char)들의 배열이기 때문에, 한 문자는 배열의 한 부분을 나타낸다. 또한 문자열의 끝을 알려주기 위해 문자열의 마지막에는 '널 종단'값이 위치한다.
| D | A | T | A | \0 |
| a[0] | a[1] | a[2] | a[3] | a[4] |
결국 변수 a는, 이러한 문자열들을 가리키는 포인터의 역할을 하고 있는 것이다. 위의 표를 예시로, 정확하게는 문자열의 시작인 'D'가 있는 a[0]을 가리킨다.
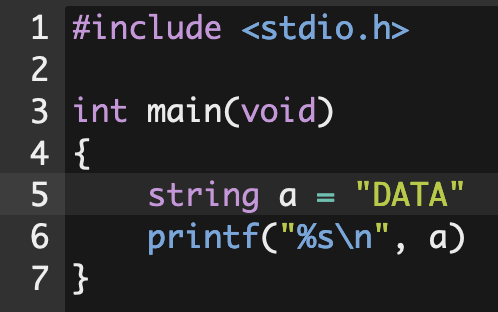

만약, cs50라이브러리를 포함하지 않고 string을 작성할 경우엔 컴파일이 되지 않는다. 실제 CS50라이브러리를 보면 string 자료형은 아래와 같이 정의되어 있다.
typedef char *string


string 대신 char *변수이름을 이용한 다음, 어느 위치에 저장되어 있는지 보기 위해 %p를 이용하여 a와 &a로 모든 값을 출력해봤다. a와 &a[0]의 값이 같음을 통해 포인터는 시작점을 가리키고 있음을 확인할 수 있다. 또한 이어지는 다른 문자들이 1바이트씩 차례대로 그 값이 증가함을 통해 순서대로 저장되어 있음을 알 수 있다.
4. 문자열 비교
4.1 구문 설탕 (syntactic sugar)

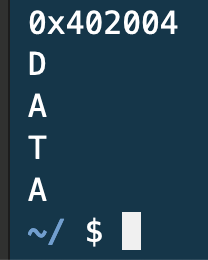
정리하자면, char *a에 "DATA"라는 문자열을 할당할 경우 a에는 "DATA" 문자열의 시작인 "D"의 메모리 주소가 할당된다. 따라서 출력시 *a를 입력하면 D가 나오게 되고, *a에 수를 더하면 더한 수만큼 뒤에 있는 글자가 출력된다. 포스트 내 3. 문자열에서 a[0], a[1]…처럼 대괄호로 배열을 출력하는 것은 '구문 설탕(syntactic sugar | 문법 설탕)'이라고 하는데 프로그래머에게 유용한 기능을 의미한다. 이렇게 코드를 작성하면 컴퓨터 내부에서 clang 컴파일러가 바로 위에 사용한 주소값 출력 방식으로 알아서 바꿔 준다.


덧붙여, printf("%s", a)를 입력하면 알아서 문자열 전체를 불러올 수 있는 건 printf의 형식 지정자가 문자열 내의 널 종단까지 계속해서 문자를 불러오기 때문이다.
4.2 문자열 비교하기


4강 알고리즘> 3. 선형 검색> 3.1.2 문자열의 비교(관계연산자)에서 문자열의 비교는 문자 하나하나를 비교해주어야 하기 때문에 관계연산자로 직접 비교를 할 수 없다고 했다. 맞는 말이지만, 포인터를 배운 지금 이 시점에서 보다 정확하게 이야기하자면 포인터가 가리키고 있는 주소 값이 다르기 때문에 그렇다. 아래의 표를 가상의 메모리 공간이라고 가정한 후 위의 코드를 나타내봤다.
| string a (0x123) |
0x123▶︎ | D | A | T | A | \0 | |||||
| string b (0x789) |
0x789▶︎ | D | A | T | A | \0 |
즉, a와 b는 각각 문자열의 첫 글자에 대한 주소값을 저장하기 때문에 같은 글자를 입력 후 비교하더라도 주소가 다르기 때문에 다르다는 출력을 내보낸다.

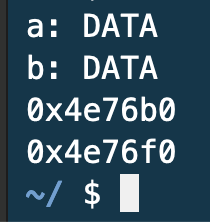
코드를 통해 주소 값을 출력해내어 직접 확인한 결과 몇 바이트의 차이를 두고 떨어져 있는 것을 알 수 있다.
5. 문자열 복사(strcpy)


사용자로부터 소문자로 이루어진 단어를 입력받은 뒤 해당 단어의 첫글자를 대문자로 바꾸기 위해 변수 a를 다시 b에 저장 후 toupper함수를 적용한 뒤 출력해 본 것이다. 오른쪽의 결과를 보면, 함수를 직접 적용한 b외에도 변수 a까지 해당 함수가 적용된 것을 볼 수 있다.
string a와 b는 위에서 배웠듯 char *a, char *b이다. 결국 b가 저장한 것은 문자열 자체가 아니라 주소 값이므로 b에 적용된 함수는 a에까지 적용되어 a와 b모두 같은 결과를 출력한 것이다.
| string a (0x123) |
0x123▶︎ | d | a | t | a | \0 | |||||
| string b (0x123) |
따라서 주소값을 복사할 것이 아니라, 메모리를 추가로 사용해서 string a와 동일한 크기로 그 값을 저장할 수 있도록 해줘야한다.


추가로 메모리를 사용하기 위해 malloc 함수로 메모리를 할당하는데, 이때 strlen함수도 함께 사용하여 문자열의 길이 + 널 값만큼 할당할 수 있도록 했다.
데이터 복사는 for 루프를 통해서 가능한데, for(int i = 0; i <= strlen(a); i++)보다 변수 n을 따로 포함해서 for (int i = 0, n = strlen(a); i<=n; i++)로 작성하는 것이 더 효율적이라고 한다. 코드 실행 후 결과를 보면 제대로 복사된 후 toupper 함수가 적용된 것을 볼 수 있다.


나아가 for 루프 대신 strcpy 함수를 사용하여 보다 간단하게 코드를 수정할 수 있다. strcpy(복사본을 저장할 위치, 복사하려는 값)을 입력하면 된다.
6. 메모리 할당과 해제 (malloc과 free)
6.1 valgrind를 통해 코드 내 메모리 문제 디버깅하기
malloc을 이용해서 메모리를 할당해준 뒤엔 다시 메모리를 반환하도록 해야 프로그램이 더 많은 메모리를 사용할 수 있다. 만약 그렇지 않을 경우엔 프로그램이 동작하는 동안 컴퓨터가 점점 느려지고 메모리 부족으로 인한 에러 메시지 창까지 띄우게 된다.

앞선 코드에서는 malloc으로 메모리를 할당한 뒤 이를 해제하는 명령을 따로 적지 않았기 때문에 사실상 오류가 포함된 코드다. 이렇게 메모리와 관련된 문제를 찾아내기 위한 디버깅 도구로는 valgrind가 있다.

valgrind 실행 결과 malloc과 관한 오류 메시지를 출력하는 것을 볼 수 있다. 보다 정확하게 문제점을 알고 싶다면 help50 valgrind ./파일명을 입력해주면 된다.

help50을 통해 살펴본 결과, malloc으로 할당한 메모리를 free로 해제시켜주는 것을 잊지 않았냐고 보다 구체적으로 묻고 있다.

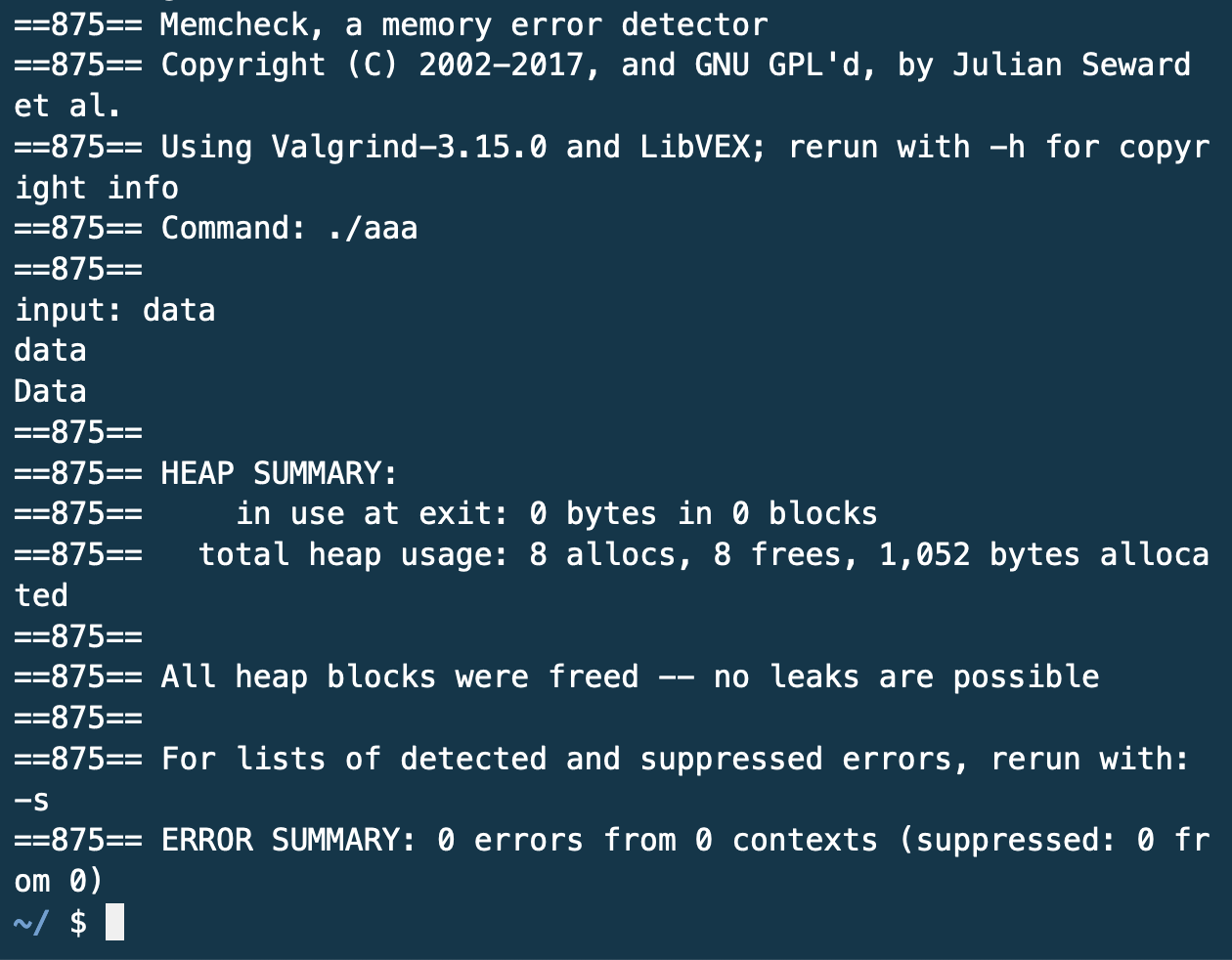
코드 마지막에 free로 malloc으로 할당된 메모리를 해제해 준 뒤 valgrind를 다시 실행시켜본 결과 메모리 누수에 대한 부분이 사라졌다.
6.2 버퍼 오버플로우 (buffer overflow)
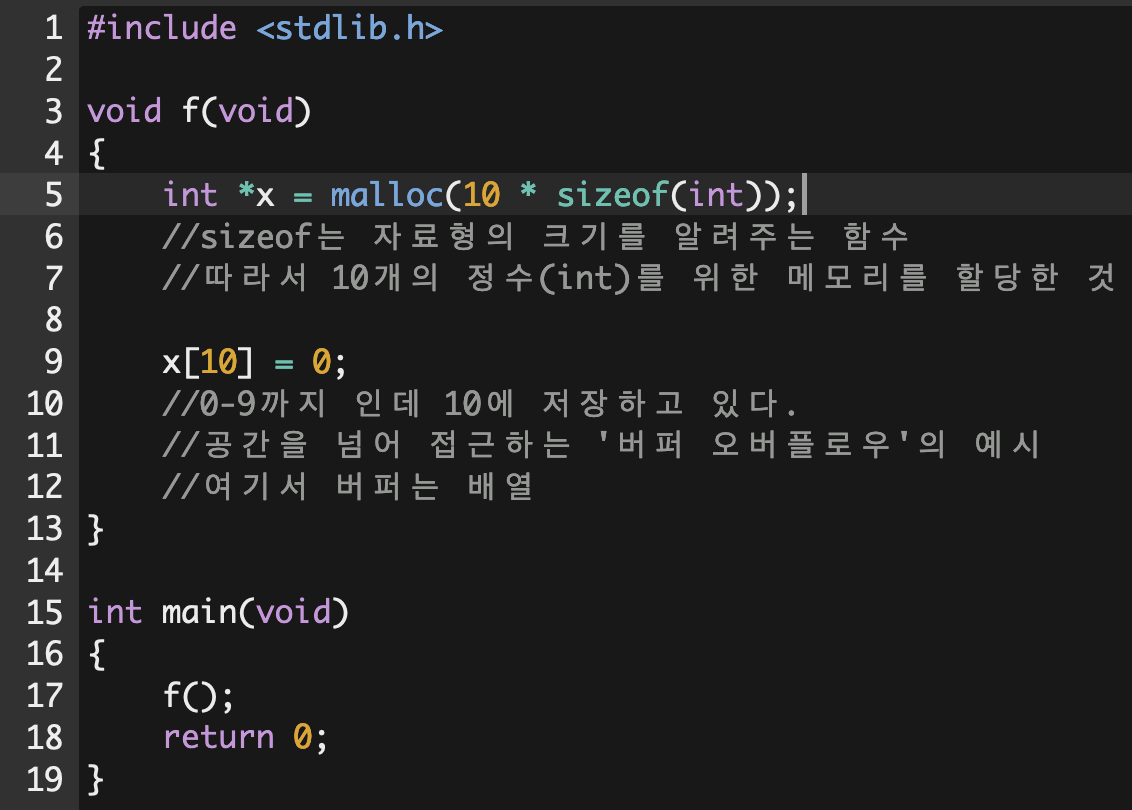
위의 코드에는 2가지 오류가 포함되어 있다. valgrind를 통해 구체적인 오류를 출력해내면 아래와 같다.

먼저 첫번째는 하이라이트 되어있는 부분처럼 malloc을 실행한 이후 free로 해제하지 않은 오류이고, 다음으로는 상단에 나와있는 invalid write of size 4이다. 코드에 미리 주석으로 표기한 것처럼, 배열에 할당된 공간을 넘어서 접근하는 버퍼 오버플로우에 대해 지적하고 있는 것이다.


두 가지 모두 수정 후 다시 valgrind를 실행한 결과 오류가 사라졌다. valgrind를 이용하면 프로그램이 갑자기 멈추거나 죽거나 세그먼테이션 오류같은 것이 일어났을 때 원인을 찾는 데 도움이 된다고 한다.
7. 메모리 교환, 스택, 힙 (swap, stack, heap)
7.1 swap 함수 오류

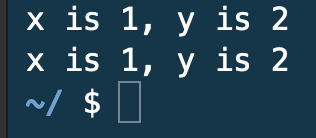
위의 코드는 swap 함수를 실행하더라도 x, y를 swap하는 것이 아니라, 함수 내에서 x, y값을 복사한 후 새롭게 정의된 a,b만 교환 후 종료되기 때문에 의도한 대로 교환이 실행되지 않는다. 즉, x, y와 a, b는 서로 다른 메모리 주소에 저장되기 때문에 x, y값에는 변화가 없는 것이다 (포스트 내 5. 문자열 복사와는 반대되는 상황이라고 볼 수 있다).
7.2 메모리 저장 방식
C를 사용할 때 컴퓨터는 메모리의 아무 공간이나 사용하는 것이 아니라, 특정 자료형에 따라 구분하여 저장한다.

위의 그림은 메모리 저장 방식의 순서에 대한 이해를 돕기 위한 대략적인 이미지로, 실제로 각 구역의 크기는 코드 구성에 따라 달라진다.
- 맨 위부터 살펴보면, 가장 먼저 컴파일된 이진수가 메모리 상단의 머신코드 영역(machine code)에저장된다.
- 그 아래에 있는 글로벌 영역(globals)에는 전역 변수나 정보에 대한 것이 저장된다.
- 글로벌 영역 아래에 있는 힙(heap)은 메모리를 할당받을 수 있는 공간으로,
malloc을 사용할 경우 이 힙에 있는 공간을 할당받게 된다. 힙은 아래로 자라나기 때문에 메모리를 사용할수록 점점 더 아래로 내려간다. - 반면 스택은 메모리 제일 아래 영역에 놓이는데, 프로그램에서 호출한 함수와 함수의 지역 변수들이 저장된다. 다른 함수를 호출할수록 위로 점점 쌓이게 된다.
이러한 규칙은 사람들이 컴파일러를 만들 때 메모리를 이렇게 구성하기로 한 약속에 따라 정해진 것이다.
7.3 stack
예시 코드를 실행했을 때 스택에서 일어나는 변화만 살펴보면 아래와 같다.

main함수를 호출하면 맨 아래에 스택 프레임이라는 공간이 주어진다. argv, argc 그리고 x, y같은 지역 변수들을 저장하는 공간으로, main 함수 안에 있는 변수는 모두 이 메모리 영역에 저장된다. main 함수가 swap같은 함수를 호출하면 해당 함수를 위한 메모리 영역이 main 위로 쌓인다. 예시 코드내의 변수까지 가시화하면 아래와 같은 구성이 될 것이다.


a와 b의 값은 x, y와 동일하지만 복사본이다. 그리고 성공적으로 교환이 완료되면 해당 프레임은 사라진다. 이 과정은 마치 식당에서 새로운 식판을 계속 위에 쌓은 다음 맨 위부터 꺼내는 것과 비슷하다고 한다. 메모리는 여전히 존재하지만 프로그램을 위해 더이상 실행하지 않는 것이다. 따라서 main 함수만 남게 되는데, 복사본에서만 교환이 이루어졌으므로 main 함수는 변화가 일어나지 않아 출력에서 변화가 없었던 것이다.

그러므로 main에서 x와 y의 값을 swap에게 전달하지 않고, x와 y의 주소를 알려주도록 한 뒤 swap함수가 그 주소가 가서 값을 바꾸게 한 다면 원하는 결과를 얻을 수 있다.


수정 후에는 원하는 대로 swap이 적용된 것을 확인할 수 있다.
8. 파일 쓰기
8.1 힙 오버플로우(heap overflow)와 스택 오버플로우(stack overflow)
7.2 메모리 저장 방식에서 다뤘던 것 처럼 heap과 stack은 각각의 화살표 방향으로 점차 메모리 영역을 확대한다. 따라서 각 영역이 계속해서 커지기만 한다면 두 메모리 영역이 충돌하는 순간이 생기게 된다.
가령 스택영역에서 재귀함수를 사용했는데 시작점없이 자기 자신을 계속해서 호출하기만 한다면 스택 오버플로우(stack overflow)를 겪게 될 것이다.
반대로 malloc을 계속해서 호출해서 너무 많은 메모리를 할당한다면 메모리 속 다른 내용을 덮어쓰는 현상이 발생하게 된다. 메모리는 한정되어 있기 때문에 너무 많은 메모리를 쓰다보면 파일이나 사진이 열리지 않거나 화면이 정지 또는 종료되는 것이다. 이런 현상은 힙 오버플로우(heap overflow)라고 한다.
8.2 CS50 라이브러리 내의 함수(get_int, get_string)
#include <stdio.h>
//get_int 함수
int main(void)
{
int x;
printf("x: ");
scanf("%i", &x);
printf("x: %i\n", x);
}사용자로부터 입력 받은 정수의 값을 저장하기 위해 scanf함수를 사용한 것을 볼 수 있다. 7.1 swap 함수 오류에서 다뤘던 것과 마찬가지로 이때 x의 복사본을 전달하는 것이 아니라 x의 주소값(&x)를 전달하여 해당 주소에 있는 값을 저장하도록 했다. 만약 주소값을 적지 않고 변수만 입력한다면 문법 오류로 컴파일 단계에서 오류가 발생한다.

#include <stdio.h>
//get_string 함수 예시
int main(void)
{
char s[5];
printf("s: ");
scanf("%s", s);
printf("s: %s\n", s);
}위의 코드는 컴파일-실행에 문제가 없는 최종 단계로, 강의에서 처음에는 아래와 같이 get_int 코드에서 부분적으로 수정한 코드를 실행했다.


그러나 이 코드는 변수 s를 주소로 초기화하지 않았기 때문에(메모리 공간을 할당하지 않았기 때문에) 컴파일 단계에서 에러가 난다.


char *s = NULL(특별한 포인터로 가리키는 공간이 없음. 빈공간을 의미)이라고 입력할 경우 컴파일 단계에서는 에러가 나지 않지만, 메모리가 할당되지 않았기때문에 프로그램이 원하는대로 작동하지 않는다.


따라서 최종적으로 사용자가 4글자를 입력한다는 가정 하에 널 종단을 포함하여 크기 5의 문자 배열을 선언하고 scanf에 주소를 전달하는 방식으로 코드를 수정한 것이다. 배열, 여기서는 정확히 문자열,은 메모리가 연속적으로 할당된 공간이고, 문자열은 그 메모리의 공간 첫번째 주소를 의미한다. 따라서 이 코드의 문맥상으로는 배열이 포인터의 역할을 하게 된다. 또한 clang 컴파일러는 문자 배열의 이름을 포인터처럼 다루기 때문에 scanf에서 굳이 &를 붙여줄 필요없이 배열의 이름만 입력해도 제대로 작동하게 된다.
그러나 위의 코드는 4글자만 입력 받도록 되어있기 때문에 4글자를 초과하면 제대로 작동하지 않는다. 글자에서 나아가 커다란 문단을 입력하기라도 한다면 프로그램이 멈추거나 세그먼테이션 오류가 발생할 수도 있다.
8.3 csv(comma separated value) 파일 쓰기

아래는 예시 코드 내용에 대한 설명이다.
- File *file = fopen("phonebook.csv", "a");
FILE이라는 새로운 자료형을 가리키는 포인터 변수*file생성.file은 변수의 이름이고 사용자가 입력한 내용을 파일로 저장함. (엄밀히 말하면 아닌데, 일단 임시로 그렇다고 함 ㅋㅋ)fopen은 첫번째 인자로 "열고싶은 파일 이름"을, 두번째 인자로 r(읽기), w(쓰기), a(덧붙이기. 파일에 계속 추가함)를 받는다. 또한fopen은 해당 파일을 가리키는 포인터를 반환한다. - char *name = get_string("Name: ");
char *number = get_string(Number: ");
편의상 CS50 함수내get_string을 사용했다.scanf를 써도 되지만, 에러 확인을 더 많이 해야한다. - fprintf(file, "%s, %s\n", name, number);
fprintf는 파일용printf라고 이해하면 되는데, 파일에 저장되는 방식을 지정하면 된다. - fclose(file);
fclose로 파일을 닫는다.



코드를 컴파일 후 실행한 다음 이름-전화번호를 입력하면 바로 csv파일이 생성되는 것을 볼 수 있다.


한 번 더 과정을 반복해보면 csv파일에 자료가 추가되는 것을 볼 수 있다. 해당 파일을 외부에서도 사용하기 위해 다운로드 받고 싶다면, phonebook.csv> 마우스 오른쪽 버튼 클릭> Download를 클릭하면 된다.

다운로드 후 맥 앱 Numbers로 실행해본 결과 제대로 저장된 것을 확인할 수 있었다.
9. 파일 읽기
9.1 JPEG 매직 넘버(파일 시그니처)
이미지 파일 확장자 중 하나인 jpeg 형식에 관한 설명 문서를 보면, 파일의 첫 세바이트는 무조건 0xFF, 0xD8, 0xFF로 시작한다. jpeg 개발자들이 정한 일종의 매직 넘버(파일 시그니처, file signature)로, 파일의 시작점에서 파일 형식이 jpeg라는 것을 알려주기 위한 것이다.
참고: 헤더 시그니처(header signature)와 푸터 시그니처(footer signature/Tailor signature)
File Magic Number (파일 매직 넘버) = File Signature (파일 시그니처)
File Magic Number (파일 매직 넘버) = File Signature (파일 시그니처) 파일들은 각각 고유...
blog.naver.com
9.2 매직 넘버(Magic Number)를 이용하여 파일 검사하기

- int main(int argc, char *argv[])
메인 함수는int argc(입력 개수)와char *argv[](문자열)를 입력으로 받는다. - if (argc != 2)
사용자가 프로그램 이름 외에도 파일명을 입력할 수 있도록 조건을 설정했다. 입력란에 프로그램+파일명 2개가 입력되지 않으면 1을 반환한다. - File *file = fopen(argv[1], "r")
사용자가 입력한 파일명은 두번째 문자열 이므로argv[1]을r(읽기)로 불러온다. - if (file == NULL)
파일에 에러가 있다면 1을 반환한다. - unsigned char bytes[3];
fread(bytes, 3, 1, file);
불러온 파일에서 3바이트를 읽는 명령.fread(배열, 읽을 바이트 수 , 읽을 횟수, 읽을 파일)입력. - if (bytes[0] == 0xff && bytes[1] == 0xd8 && bytes[2] == 0xff)
만약 파일의 첫 세바이트가 위에 해당한다면, jpeg일 수도 있다는 결과 출력 - else
위에 해당하지 않을 경우 No 출력 - fclose(file)
함수 종료
강의에서는 예시 코드를 통해 작동하는 테스트만 진행해서 매우 빠르게 진행됐다. 함수에 대한 보다 자세한 설명 등은 이후 강의에서 다룰 것으로 예상.
주차가 지날수록 다루는 내용이 눈덩이 불어나듯이 늘어나는데,
그나마 설연휴 덕에 한숨 돌렸다.

'STUDY > boostcourse' 카테고리의 다른 글
| [부스트코스] CS50 코칭스터디 2기 수료 후기 (0) | 2021.03.03 |
|---|---|
| [부스트코스] CS50 6강: 자료구조 강의 정리 (부제: CS50 수강 완료!) (2) | 2021.02.23 |
| [부스트코스] CS50: 초보자는 헷갈리는 C언어 용어 정리 (0) | 2021.02.12 |
| [부스트코스] CS50 4강: 알고리즘 강의 정리 (부제: 아직 2주나 혹은 벌써 2주 남은 코칭 스터디) (0) | 2021.02.05 |
| [부스트코스] CS50 3강: 배열 강의 정리 (부제: 코칭스터디 3주차) (0) | 2021.01.29 |